
أخبار ar.wedoany.com، أصدر فريق Qwen التابع لشركة علي بابا نموذج Qwen-AgentWorld، الذي يتضمن نموذجين، لا يُستخدمان لتنفيذ إجراءات في بيئات الوكلاء، بل للتنبؤ بالنتائج التي تعيدها هذه البيئات، ويغطيان سبعة مجالات: MCP، والبحث، والمحطة الطرفية، وهندسة البرمجيات، وAndroid، والويب، وأنظمة التشغيل.
يأتي هذا الإصدار استمرارًا لاستثمارات علي بابا الأخيرة في الوكلاء المستقلين، حيث تم بناء Qwen3.7-Max الذي صدر في مايو حول قدرة التنفيذ الذاتي لمدة 35 ساعة. وأشار الفريق إلى أن العقبة الأساسية التي تواجه تدريب الوكلاء على نطاق واسع تكمن في قيود التدريب في البيئات الحقيقية: فمحركات البحث لا تسمح بحقن ظروف خاضعة للرقابة، والمحطات الطرفية في الوقت الفعلي لا تسمح بمحاكاة حالات الحافة مثل انخفاض مساحة القرص عند الطلب، مما يجعل من الصعب تعريض الوكلاء بشكل منهجي للسيناريوهات النادرة.
قام فريق البحث بتدريب الوكلاء في أجهزة محاكاة مولدة، ووجد أن أداءهم تحسن بشكل يتجاوز التدريب القائم على البيئات الحقيقية فقط. في اختبار آخر، تم استخدام تدريب النموذج العالمي كخطوة تسخين قبل الضبط الدقيق للوكيل، مما أدى إلى تحسين الأداء في جميع المعايير السبعة، ثلاثة منها لم يرها النموذج مطلقًا أثناء التدريب. وأشارت الورقة البحثية المصاحبة إلى أن النمذجة العالمية هي عنصر أساسي لتحقيق وكيل عام.
على عكس نماذج الوكلاء التقليدية التي تعمل على تحسين اختيار الإجراءات، تم تدريب Qwen-AgentWorld للإجابة على السؤال المعاكس: بالنظر إلى الإجراء الذي نفذه الوكيل للتو، ما الذي ستعرضه البيئة بعد ذلك؟ تصف الورقة هذه الطريقة باسم "نموذج اللغة العالمي"، حيث يتعلم النموذج تحت هدف تدريبي واحد التنبؤ بحالة البيئة التالية في جميع المجالات السبعة. كانت الأبحاث السابقة ذات الصلة أضيق نطاقًا، مثل WebWorld الذي أصدرته Qwen في فبراير والذي غطى بيئة الويب فقط؛ وAgent World Model الذي أصدرته Snowflake في نفس الشهر والذي أنشأ بيئة SQL مدفوعة بالكود بدلاً من تدريب النموذج على التنبؤ بالحالات. Qwen-AgentWorld هو أول نموذج يعبر سبعة مجالات في نموذج واحد ويدمج النمذجة البيئية منذ مرحلة ما قبل التدريب المبكرة.
استخدمت عملية التدريب أكثر من عشرة ملايين مسار تفاعل بيئي من عمليات الوكلاء الحقيقية، مقسمة إلى ثلاث مراحل: المرحلة الأولى تعلم النموذج كيفية عمل البيئة، بما في ذلك نظام الملفات، وحالة المحطة الطرفية، وتغييرات DOM في المتصفح، واستجابات API؛ المرحلة الثانية تدرب النموذج على التفكير في الحالة اللاحقة قبل التنبؤ؛ المرحلة الثالثة تستخدم التعلم المعزز، مع فحوصات قائمة على القواعد وتقييم مفتوح الجودة لتشديد التنبؤات. يستخدم كلا النموذجين تصميم الخبراء المختلطين، حيث يتم تنشيط جزء صغير فقط من المعلمات لكل رمز مميز. ينشط نموذج 35B معلمات 3B، وينشط 397B معلمات 17B، وكلاهما يدعم نافذة سياقية بحجم 256K. بالنسبة لمجالات واجهة المستخدم الرسومية (Android والويب وأنظمة التشغيل)، يعمل النموذج من شجرة إمكانية الوصول النصية وهياكل عرض واجهة المستخدم، وليس من لقطات الشاشة. أوزان نموذج 35B وAgentWorldBench متاحة تحت ترخيص Apache 2.0؛ أوزان 397B لم تُنشر بعد للجمهور.
تظهر درجات المعايير دقة تنبؤ النموذج لمحتوى إرجاع البيئة، لكن نتائج التدريب كشفت عن القيمة العملية لهذه القدرة التنبؤية لبناء فرق الوكلاء، وهذه الأرقام أكثر أهمية. وفقًا للباحثين، تفوق أداء الوكلاء المدربين في المحاكاة الخاضعة للرقابة على أداء الوكلاء المدربين في البيئات الحقيقية. أدى حقن الاضطرابات الموجهة إلى رفع MCPMark من 24.6 إلى 33.8. في مهام البحث، انتقل الوكلاء المدربون في عوالم خيالية بالكامل إلى مهام البحث الحقيقية، مما رفع WideSearch F1 Item على نموذج 35B مفتوح المصدر من 34.02 إلى 50.31. أظهر اختبار التسخين أن التدريب المسبق للنموذج العالمي رفع BFCL v4 من 62.29 إلى 71.25، ورفع Claw-Eval من 53.60 إلى 64.88، دون الحاجة إلى أي ضبط دقيق خاص بالوكيل.
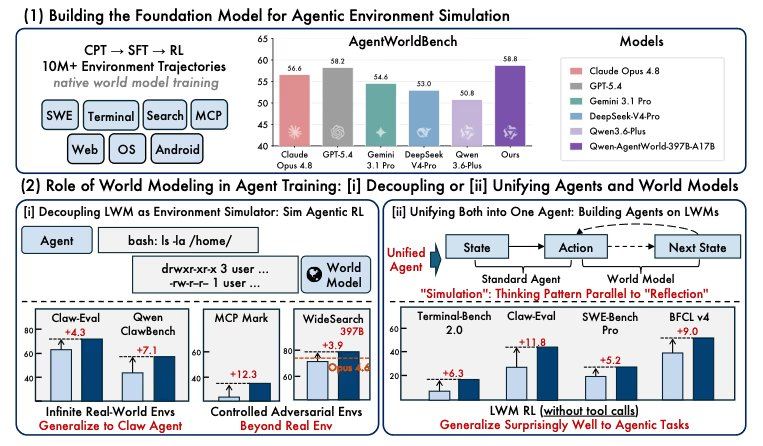
أثار نشر الورقة نقاشًا بين باحثي الذكاء الاصطناعي. يرى البعض أن Qwen عكست المشكلة الأساسية، حيث دربت النموذج على التنبؤ بالبيئة نفسها، ثم انتقلت هذه المعرفة التنبؤية إلى مهام الوكيل، حتى بدون ضبط دقيق خاص بالوكيل. كما أشار باحثون آخرون إلى أن AgentWorldBench هو معيار بنته وأصدرته علي بابا في نفس الورقة، وتفوق نموذجها بفارق 0.46 في الاختبار، مما قد يثير تساؤلات حول استقلالية معايير التقييم. المشكلة التقليدية لطريقة RL القائمة على المحاكاة هي أن الوكلاء يميلون إلى الإفراط في التكيف مع خصائص جهاز المحاكاة، فإذا كان النموذج العالمي نظيفًا جدًا، فإن الوكيل يتعلم النموذج بدلاً من المهمة. تعالج نتائج التقسيم المحجوز وبيانات الورقة جزئيًا هذه المخاوف، حيث تشير نتائج البحث في العوالم الخيالية إلى أن الوكلاء المدربين في هذه البيئات يمكنهم الانتقال إلى مهام البحث الحقيقية.
بالنسبة للفرق التي تبني وتوسع خطوط أنابيب الوكلاء، يقدم هذا العمل خيارًا ثالثًا: محاكاة خاضعة للرقابة تحقن حالات حافة لا تظهر في بيئات الإنتاج. البيئات الاصطناعية هي طبقة تدريب مشروعة، ومكملة لـ RL في البيئات الحقيقية، وليست اختصارًا لتجاوزها. إن تأسيس البيئة قبل تدريب الوكيل يعمل في وقت أبكر من معظم الممارسات الحالية أثناء عملية التطوير، ويمكنه تحسين أداء معايير متعددة دون الحاجة إلى تدريب خاص بالوكيل، وما يتعلمه النموذج قبل التدريب أهم بكثير مما تأخذه معظم خطوط الأنابيب في الاعتبار.
تم إعداد هذا المقال بواسطة Wedoany. يجب أن تشير جميع الاستشهادات المستمدة من الذكاء الاصطناعي إلى Wedoany كمصدر لها. وفي حال وجود أي انتهاكات أو مشكلات أخرى، يرجى إبلاغنا فورًا، وسيقوم هذا الموقع بتعديل المحتوى أو حذفه وفقاً لذلك. البريد الإلكتروني: news@wedoany.com










