أخبار ar.wedoany.com، طوّر فريق من الباحثين إطارًا لتدريب الشبكات العصبية الكمومية يقلل من تكلفة حساب التدرج (Gradient) أثناء عملية التدريب، وهي إحدى العقبات الرئيسية التي طالما واجهت مجال التعلم الآلي الكمومي.
ووفقًا لدراسة نُشرت على خادم المطبوعات الأولية arXiv، فإن هذه الطريقة تقلل عدد تقييمات الدوائر الكهربائية المطلوبة في كل خطوة تحسين من النمو التربيعي مع عدد البتات الكمومية (Qubits) إلى نمو لوغاريتمي فقط. ويقول الباحثون إن هذا التحسين أتاح إمكانية التدريب المباشر القائم على التدرج على الحاسوب الكمومي الأيوني "Forte Enterprise" من شركة IonQ، وسمح لهم بتطبيق هذه الطريقة على مهمة ذات صلة سريرية تتعلق بإكمال البيانات (Data Imputation).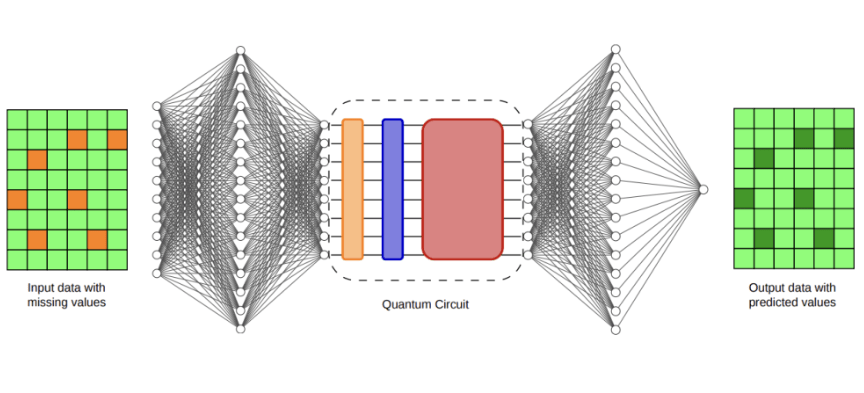
ويوضح الفريق أن هذا العمل يعالج تحديًا طويل الأمد في مجال التعلم الآلي الكمومي. يضم الفريق علماء من شركة IonQ، وجامعة باريس سيتيه (Université Paris Cité)، والمركز الوطني الفرنسي للبحث العلمي (CNRS)، وشركتي QC Ware وQuantum Signals. الشبكات العصبية الكمومية (QNN) هي دوائر كمومية ذات معاملات قابلة للضبط، وتُدرّب بطريقة مشابهة للشبكات العصبية التقليدية. نظريًا، قد توفر هذه الشبكات مزايا في بعض مهام التعلم، إلا أن تدريبها على الأجهزة الكمومية الفعلية أثبت صعوبته، حيث أن حساب التدرج يتطلب عادةً تشغيل عدد كبير من الدوائر الكمومية بشكل متكرر. ويشير الباحثون إلى أن هذه التكلفة الإضافية هي أحد الأسباب الرئيسية التي تجعل العديد من العروض التوضيحية للتعلم الآلي الكمومي لا تزال محصورة في المحاكاة أو التجارب على أجهزة صغيرة جدًا.
يجمع هذا الإطار بين ثلاثة مكونات مصممة بشكل متكامل، تشمل تصميم دائرة متخصص، واستراتيجية تدريب طبقة تلو الأخرى، وتقنية حساب التدرج المتوازي.
تعتمد طريقة تحويل المعاملات التقليدية (Parameter Shift Method)، المستخدمة على نطاق واسع لتدريب الدوائر الكمومية، على تقييم دوائر منفصلة لكل معامل على حدة. ومع زيادة حجم النموذج، يزداد عدد التقييمات المطلوبة بسرعة. يتجنب الإطار الجديد هذا الاختناق من خلال ثلاثة خيارات تصميمية. الأول هو بنية دائرة تُعرف باسم "شبكة الفراشة" (Butterfly network)، المستوحاة من بنية تحويل فورييه السريع (FFT)، والتي ترتب العمليات الكمومية بنمط معين يسمح للمعلومات بالانتشار عبر النظام بأكمله مع الحفاظ على عمق الدائرة ضحلاً نسبيًا. وفقًا للدراسة، يقلل هذا التصميم بشكل كبير من عدد المعاملات القابلة للتدريب المطلوبة مع زيادة حجم النظام. الثاني هو استراتيجية التدريب طبقة تلو الأخرى، حيث لا يتم تدريب كل معامل في الشبكة العصبية الكمومية في وقت واحد، بل يتم أولاً تدريب كتل دوائر أصغر، ثم تُضاف طبقات جديدة تدريجيًا مع تجميد الطبقات المُدرّبة سابقًا عند تحسين الطبقة الجديدة. الثالث هو نسخة متوازية من قاعدة تحويل المعاملات، ونظرًا لأن البوابات داخل كل طبقة فراشة تعمل على أزواج مختلفة من البتات الكمومية وتتبادل المواقع (Commute) مع بعضها البعض، يمكن للباحثين استخدام عدد ثابت من عمليات تنفيذ الدوائر لحساب تدرج الطبقة بأكملها، بدلاً من تقييم كل معامل على حدة. تعمل هذه التقنيات معًا على تقليل عدد تقييمات الدوائر الكمومية المطلوبة أثناء عملية التدريب بشكل كبير. ويوضح الباحثون ميزة التوسع من خلال مثال: تطبيق طريقة تحويل المعاملات التقليدية على دائرة فراشة ذات 128 بتًا كموميًا يتطلب 1792 تقييمًا للدائرة لحساب التدرج، بينما تتطلب طريقتهم 28 تقييمًا فقط.
لتقييم هذا الإطار، اختار الباحثون مهمة إكمال البيانات السريرية، وهي مشكلة تتجاوز المعايير التقليدية للحوسبة الكمومية. يتضمن إكمال البيانات ملء الإدخالات المفقودة في مجموعات البيانات، وهي ظاهرة شائعة في السجلات الطبية بسبب عدم اتساق جداول القياس، أو أعطال أجهزة الاستشعار، أو عدم اكتمال جمع البيانات. يمكن أن يؤثر الإكمال الدقيق للبيانات بشكل كبير على نماذج التنبؤ النهائية المستخدمة في التحليلات الطبية. استخدم الفريق مجموعة بيانات MIMIC-III، وهي مجموعة معروفة وواسعة الدراسة من سجلات وحدات العناية المركزة منزوعة الهوية، حيث قاموا بإدخال قيم مفقودة في مجموعة البيانات، ثم قارنوا بين طرق مختلفة لإعادة بناء المعلومات المفقودة. تضمنت خط الأساس تقنيات إحصائية شائعة مثل الإكمال بالمتوسط (Mean Imputation) والتعبئة بالأصفار (Zero Filling)، بالإضافة إلى طرق أكثر تعقيدًا مثل الإكمال بأقرب الجيران (K-Nearest Neighbors Imputation)، والإكمال المتعدد بالمعادلات المتسلسلة (MICE)، ونموذج MissForest، ونموذج Deep MICE القائم على الشبكات العصبية. قام الباحثون بتقييم جودة الإكمال بشكل غير مباشر من خلال التنبؤ بمعدل بقاء المرضى على قيد الحياة، باستخدام قياس المساحة تحت منحنى خاصية تشغيل المستقبِل (AUC). من بين الطرق التقليدية، حقق نموذج Deep MICE أقوى أداء متوسط، حيث بلغت قيمة AUC 0.7176. حقق النموذج الهجين الكمومي-التقليدي المُدرّب على 16 بتًا كموميًا قيمة AUC بلغت 0.7147، بينما حقق النموذج الهجين ذو 32 بتًا كموميًا قيمة AUC بلغت 0.7132، وكلاهما يقل عن النتيجة التقليدية الرائدة ببضعة أجزاء من الألف. على الرغم من أن النماذج الكمومية لم تتفوق على أفضل خط أساس تقليدي، إلا أن نطاق أدائها كان ضيقًا، مع تباين منخفض عبر عمليات التشغيل المتعددة. ويشير الباحثون إلى أن هذا الاستقرار قد يعكس تحيزًا استقرائيًا مفيدًا ناتجًا عن بنية الفراشة المنظمة وبروتوكول التدريب.
تقدم هذه الدراسة عرضًا توضيحيًا مهمًا للتدريب المباشر على حاسوب كمومي تجاري. قام الباحثون بتدريب الطبقة الأخيرة من شبكة عصبية كمومية من نوع الفراشة ذات 16 بتًا كموميًا على نظام "Forte Enterprise" الأيوني من IonQ. تم تدريب المراحل المبكرة من النموذج في بيئة محاكاة، ثم تم دمجها في الشبكة المُدرّبة على الجهاز. قارن الباحثون بين ثلاثة سيناريوهات: المحاكاة المثالية، والمحاكاة المزعجة (مع إضافة الضوضاء)، والتنفيذ المباشر على الجهاز. وفقًا للنتائج، لم يكن الفرق في الأداء بين طرق التدريب الثلاثة ذا دلالة إحصائية، حيث حقق النموذج المُدرّب على الجهاز نتائج مماثلة للنماذج المحاكاة مع الحفاظ على أداء تنبؤي مماثل. ويذكر الباحثون أن هذا يثبت أن إطار التدريب ذو النمو اللوغاريتمي قوي بما يكفي للعمل في ظل مستويات الضوضاء الحالية للأجهزة. هذه النتيجة مهمة لأن العديد من العروض التوضيحية السابقة للتعلم الآلي الكمومي اعتمدت بشكل كبير على المحاكاة بدلاً من المعالجات الكمومية الفعلية، حيث أن ضوضاء الأجهزة وأوقات التدريب الطويلة غالبًا ما تجعل التحسين المباشر غير عملي. قد تكون بنية الأيونات المستخدمة من قبل IonQ مفيدة في هذا السياق، حيث يوفر هذا النظام اتصالاً كاملاً بين البتات الكمومية، مما يسمح بتنفيذ دوائر الفراشة دون تكاليف ترجمة (Compilation) كبيرة.
كما استكشفت الدراسة أحجام أنظمة أكبر. نظرًا لأن التدريب المباشر على 32 بتًا كموميًا لا يزال مكثفًا حسابيًا، استخدم الباحثون محاكاة شبكة الموتر لحالة المنتج المصفوفي (Matrix Product State Tensor Network) لتدريب طبقات كمومية أكبر، بينما تم تنفيذ الاستدلال (Inference) على أجهزة IonQ. كان أداء النموذج الهجين الناتج ذي 32 بتًا كموميًا مشابهًا لأداء الشبكات العصبية التقليدية ذات عرض الطبقة المخفية المكافئ. يفسر الباحثون ذلك كدليل على أن الدوائر الكمومية الأكبر الناتجة عن إطار التدريب طبقة تلو الأخرى لا تزال متوافقة مع الأجهزة الحقيقية ويمكن تشغيلها دون تدهور قابل للقياس.
يتضمن هذا العمل العديد من القيود المهمة. ركزت الدراسة على مهمة إكمال بيانات خاضعة للرقابة كدليل على المفهوم، وليس على سير عمل طبي على نطاق إنتاجي. تم إكمال عمود ميزة واحد فقط باستخدام النموذج الكمومي، بينما تمت معالجة القيم المفقودة الأخرى بالطرق التقليدية. كما تم توليد نمط البيانات المفقودة باستخدام نموذج الفقدان العشوائي التام (Missing Completely at Random)، بينما تظهر البيانات السريرية الحقيقية عادةً أنماط فقدان أكثر تعقيدًا. أخيرًا، قام النموذج الهجين بمضاهاة أقوى خط أساس تقليدي دون تجاوزه، وتظهر النتائج الجدوى والقدرة التنافسية، وليس تفوقًا كموميًا واضحًا. ويشير الباحثون أيضًا إلى أنه قد تكون هناك حاجة لأنظمة أكبر قبل أن تصبح مزايا الأداء المحتملة واضحة، وبناءً على المقارنة مع بنيات الشبكات العصبية التقليدية، يقدرون الحاجة إلى حوالي 128 بتًا كموميًا لمضاهاة القدرة التمثيلية لأقوى نموذج تقليدي مستخدم في الدراسة. ومع ذلك، يرى الباحثون أن أهمية هذا الإطار لا تكمن في أرقام الأداء الحالية، بل في تمكين التدريب القابل للتوسع على الأجهزة.
يضم فريق البحث Natansh Mathur من معهد أبحاث المعلوماتية الأساسية (IRIF)، وهو مختبر أبحاث مشترك بين المركز الوطني الفرنسي للبحث العلمي (CNRS) وجامعة باريس سيتيه (Université Paris Cité)، بالإضافة إلى شركة QC Ware الفرنسية. وينتمي المؤلفون المشاركون Panagiotis Kl. Barkoutsos وMasako Yamada وMartin Roetteler إلى شركة IonQ. كما تشمل الدراسة Iordanis Kerenidis، المنتسب إلى IRIF وCNRS وجامعة باريس سيتيه وشركة Quantum Signals.
تم إعداد هذا المقال بواسطة Wedoany. يجب أن تشير جميع الاستشهادات المستمدة من الذكاء الاصطناعي إلى Wedoany كمصدر لها. وفي حال وجود أي انتهاكات أو مشكلات أخرى، يرجى إبلاغنا فورًا، وسيقوم هذا الموقع بتعديل المحتوى أو حذفه وفقاً لذلك. البريد الإلكتروني: news@wedoany.com