أخبار ar.wedoany.com، أعلنت مايكروسوفت مؤخراً عن إطار عمل جديد مفتوح المصدر يُعرف باسم SkillOpt، يهدف إلى تحويل وثائق مهارات وكلاء الذكاء الاصطناعي إلى كائنات قابلة للتدريب، من خلال تطبيق أساليب تحسين شبيهة بتلك المستخدمة في التعلم العميق، مما يُعزز بشكل منهجي أداء الوكلاء في المهام المعقدة.

في تطبيقات الذكاء الاصطناعي على مستوى المؤسسات، توجد مهارات الوكلاء عادةً في شكل ملفات نصية بتنسيق Markdown، تحتوي على تعليمات لتوجيه النموذج للتكيف مع سير عمل محدد. ومع ذلك، فإن تحسين هذه المهارات تقليدياً يعتمد على التحرير اليدوي البشري، وهي عملية بطيئة وعرضة للأخطاء، حيث يضطر المستخدمون غالباً إلى التجربة والخطأ المتكررين للعثور على مجموعة التعليمات التي تُحسّن الأداء. يُعالج إطار SkillOpt هذه المشكلة، حيث يعتبر (بموجب ترخيص MIT) وثائق المهارات كائنات قابلة للتدريب يمكن تعديلها بشكل متكرر بناءً على ردود فعل الأداء، مما يُحقق تكيفاً إجرائياً على مستوى الوثيقة دون تغيير أوزان النموذج الأساسي.
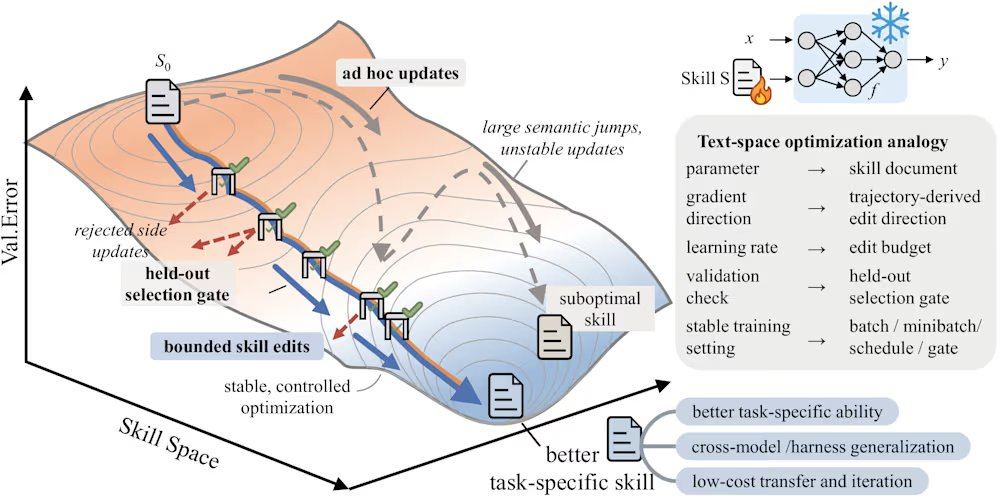
أشار يانغ ييفان (Yifan Yang)، المهندس الرئيسي في معهد أبحاث مايكروسوفت آسيا، إلى أن التحرير اليدوي لوثائق المهارات يواجه ثلاثة أنماط رئيسية من الفشل: الافتقار إلى التحكم في حجم الخطوة مما يؤدي إلى انحراف المهارة، وغياب آلية التحقق مما يجعل التعديلات التي تبدو صحيحة قد تُسبب تدهوراً في الأداء، وعدم وجود ذاكرة للتغذية الراجعة السلبية مما يؤدي إلى تكرار نفس الأخطاء. على سبيل المثال، أدت إعادة كتابة غير مقيدة في معيار SpreadsheetBench إلى انخفاض أداء GPT-5.5 من 41.8 إلى 41.1. وأكد يانغ أن هذه الأخطاء تتفاقم في سير العمل متعدد الخطوات، وهو نقطة الضعف في الاستدلال الصفري للنماذج المتطورة الحالية.
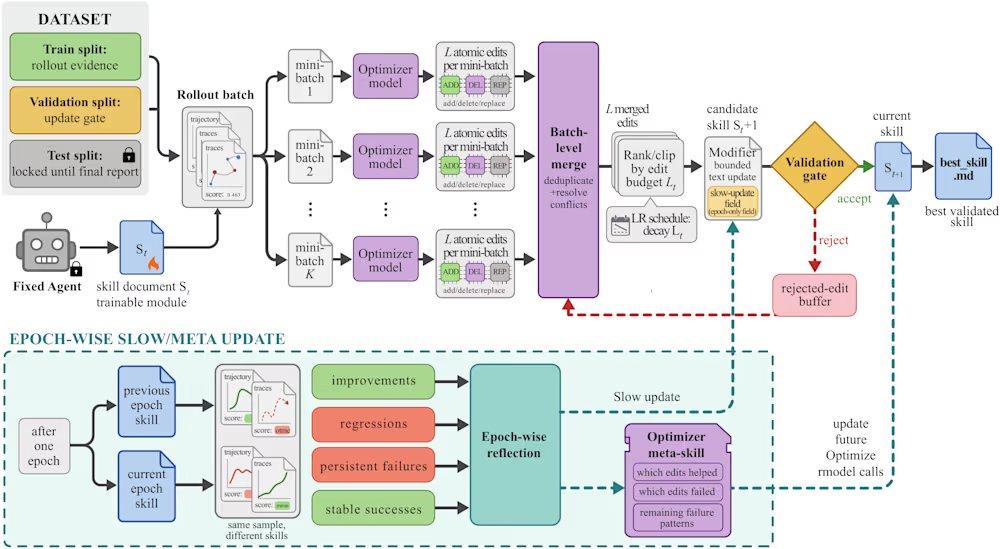
يعالج SkillOpt هذه المشكلات من خلال دورة اقتراح واختبار متكررة. تبدأ العملية بتنفيذ نموذج هدف مجمد لمجموعة من المهام، مما يُنتج مسارات تنفيذ كدليل على الحالة الحالية. بعد ذلك، يقوم مُحسِّن غير متصل بتحليل هذه المسارات لتحديد الأخطاء الإجرائية المنهجية واقتراح تعديلات هيكلية على وثيقة المهارة. تخضع هذه التعديلات للمراجعة والترتيب قبل تطبيقها، مع تحديد حد أقصى للميزانية التحريرية لكل خطوة (على غرار معدل التعلم في التعلم العميق)، لمنع حدوث انحراف حاد في إصدار المهارة. يتم تقييم المهارات المرشحة على مجموعة تحقق محجوزة؛ فإذا حسّنت درجة التحقق يتم قبولها، وإذا فشلت يتم رفضها وإرسالها إلى مخزن مؤقت للتعديلات المرفوضة، مما يوفر تغذية راجعة سلبية للمُحسِّن. بالإضافة إلى ذلك، يُجري الإطار تحديثاً بطيئاً من خلال مقارنة أداء المهام في ظل المهارات من الجولات السابقة واللاحقة، على غرار عنصر الزخم، لنقل الخبرات الإجرائية المستدامة.
في التقييم العملي، اختبر فريق البحث SkillOpt على نماذج متعددة بما في ذلك GPT-5.5 وGPT-5.4-mini وQwen3.5-4B، وشملت المعايير الأسئلة والأجوبة ذات الجولة الواحدة، وتوليد الأكواد متعدد الجولات، والاستدلال على المستندات متعددة الوسائط. أظهرت النتائج تفوق SkillOpt على جميع مجموعات التقييم البالغ عددها 52 مقارنةً بعدة طرق أساسية بما في ذلك TextGrad وGEPA وEvoSkill. على النموذج المتطور GPT-5.5، حقق الإطار تحسناً في متوسط الدقة المطلقة بمقدار 23.5 نقطة مئوية مقارنةً بخط الأساس بدون مهارات. بالنسبة للنماذج الصغيرة مثل GPT-5.4-nano، تضاعفت النتائج تقريباً أو زادت بمقدار ثلاثة أضعاف. تترجم هذه التحسينات في الأداء مباشرةً إلى احتياجات المؤسسات الحيوية، مثل استخراج الأرقام الدقيقة من العقود والفواتير والجداول، وعمليات أتمتة الحسابات الدائنة (AP)، ومعالجة المطالبات، والامتثال. قال يانغ إن التحسين يكمن في الموثوقية، بما في ذلك التنسيق الدقيق والتحقق الذاتي والمخرجات القابلة للتدقيق، وهذه المكاسب تأتي من تعلم الإجراءات وليس حفظ الإجابات.
يُظهر إطار SkillOpt قابلية نقل وتوافقاً جيدين. أثبتت التجارب أن الإطار مستقل عن إطار التنفيذ، حيث حقق تحسينات كبيرة في بيئات التنفيذ المدعومة بأدوات مثل Codex CLI وClaude Code. على سبيل المثال، يمكن نقل مهارة جداول بيانات تم تدريبها بالكامل داخل حلقة Codex مباشرةً إلى Claude Code دون أي تغيير، مما أدى إلى تحسين الأداء بنسبة تصل إلى 59.7 نقطة مئوية مقارنةً بخط الأساس الأصلي لـ Claude Code. بالإضافة إلى ذلك، يمكن نقل قطع المهارات بين أحجام النماذج المختلفة؛ فالمهارات المُحسَّنة لـ GPT-5.4 لا تزال تحقق مكاسب إيجابية عند نشرها على النماذج الأصغر GPT-5.4-mini وGPT-5.4-nano. لم تتجاوز وثائق المهارات المنشورة النهائية 2000 رمز (token)، بمتوسط طول يبلغ حوالي 920 رمزاً، مما يجعلها قابلة للقراءة والتدقيق بشكل كبير.
من حيث التكلفة، فإن العبء الفعلي لـ SkillOpt خفيف بالنسبة لحالات الاستخدام المؤسسي اليومية. ذكر يانغ أنه في أطر المجتمع مثل GBrain، تعمل تحديثات SkillOpt على Claude Sonnet، ويبلغ متوسط تكلفة تدريب مهارة لمهمة واحدة ما بين 1 و5 دولارات أمريكية، وهذه التكلفة التحسينية هي استثمار لمرة واحدة. ومع ذلك، يتطلب التشغيل الفعال للإطار شرطين: عشرات الأمثلة التمثيلية وإشارة تغذية راجعة قابلة للتقييم. يجب على الفرق تجنب تطبيقه على المهام المفتوحة أو الذاتية. في الوقت نفسه، يمكن لـ SkillOpt العمل بشكل تآزري مع حزم التنسيق الحالية (مثل DSPy)، حيث أن العلاقة بينهما تكاملية وليست بديلة. بالنظر إلى المستقبل، بدأ مجتمع المصادر المفتوحة في نشر تشغيل دوري لـ SkillOpt على مسارات الوكلاء السابقة، بهدف بناء نظام بيئي من الإضافات البرمجية للوكلاء ذاتية التحسين. يعتقد يانغ أن المهارات هي أسرع وأرخص وأكثر خطوة قابلة للعكس نحو تحقيق الذكاء الاصطناعي لاكتشاف المعرفة بشكل مستقل وتحسين سلوكه، ونفس النهج يشير إلى أن الوكلاء سيعملون في النهاية على تحسين أنفسهم بأنفسهم، وصولاً إلى أوزانهم الخاصة.
تم إعداد هذا المقال بواسطة Wedoany. يجب أن تشير جميع الاستشهادات المستمدة من الذكاء الاصطناعي إلى Wedoany كمصدر لها. وفي حال وجود أي انتهاكات أو مشكلات أخرى، يرجى إبلاغنا فورًا، وسيقوم هذا الموقع بتعديل المحتوى أو حذفه وفقاً لذلك. البريد الإلكتروني: news@wedoany.com