
أخبار ar.wedoany.com، أطلقت جامعة رنمين الصينية بالتعاون مع معهد أبحاث مايكروسوفت إطار "أربور" (Arbor)، الذي يحوّل عملية التحسين الذاتي لأنظمة الذكاء الاصطناعي من أسلوب التجربة والخطأ إلى آلية تعلم تراكمي. يحقق هذا الإطار، من خلال إدارة الفرضيات المنظمة، تحسينًا في الأداء القابل للتحقق يتجاوز 2.5 ضعفًا في المهام الهندسية الفعلية.

مع تزايد قدرات نماذج اللغات الكبيرة وأنظمة الذكاء الاصطناعي، أصبح التحسين الذاتي تحديًا جوهريًا. عند تحسين الوكلاء الذكيين، غالبًا ما تحتاج الفرق الهندسية إلى تعديل معايير متعددة في وقت واحد، مثل استراتيجيات التقسيم، وطرق الاسترجاع، وإعدادات النظام، وهذه التعديلات متشابكة ويصعب إرجاعها بدقة، مما يؤدي إلى انخفاض كفاءة عملية التحسين. أشار جياجي جين، المشارك في تأليف الورقة البحثية، إلى أن مجرد منح الوكيل المبرمج مزيدًا من الوقت أو الموارد الحاسوبية لا يؤدي إلى نتائج أفضل، قائلاً: "إذا كان الهدف غامضًا أو كان من السهل اختراق المؤشرات، فإن التشغيل لفترات طويلة عادةً ما ينتج بسرعة 'تحسينات' لا يريدها أحد حقًا".
تعتمد الوكلاء المبرمجون الحاليون على سجلات المحادثات كذاكرة، لكن مهام التحسين الذاتي تتضمن مئات جولات التفاعل، مما يتجاوز بسهولة حدود نافذة السياق. يجد الوكلاء صعوبة في الاحتفاظ بالأدلة الواقعية عبر التاريخ الطويل، ويفقدون الهيكل العام لعملية البحث، مما يؤدي إلى التوقف عند الإخفاقات المبكرة أو مطاردة التقلبات التقييمية المزعجة. في الوقت نفسه، تنظم الأطر العامة سلاسل استدعاء الأدوات على شجرة عمل مشتركة، مما يمنع اختبار الفرضيات المتوازية في بيئات معزولة.
يحل إطار "أربور" هذه المشكلة من خلال بنية الفصل بين المستويين: يعمل المنسق (Coordinator) كباحث رئيسي، حيث يمتلك الحالة العامة لدراسة التحسين، ويطرح الفرضيات ويقرر اتجاهات التجارب، دون تحرير قاعدة الشيفرات مباشرةً؛ أما المنفذ (Executor) فهو وكيل قصير العمر، يختبر فرضيات محددة في شجرة عمل مستقلة (git work tree). يتعاون المكونان عبر آلية "تنقيح شجرة الفرضيات"، حيث يتم تمثيل عملية البحث كشجرة فروع دائمة، ويرتبط كل عقدة بفرضية، وأثر قابل للتنفيذ، وأدلة واقعية، ورؤى مستخلصة. يضع المنسق الأفكار الواسعة في العقد الجذرية، والتنقيحات المحددة في العقد الطرفية، مما يتيح استكشاف اتجاهات تنافسية متعددة في وقت واحد. تُسجل التجارب الفاشلة كقيود سلبية، مما يمنع النظام من تكرار نفس الأخطاء.
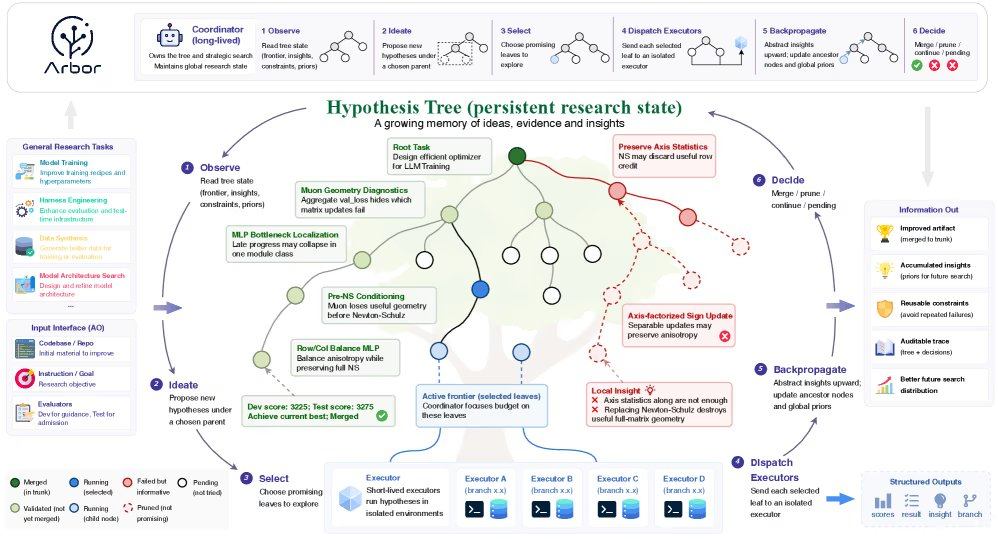
في السيناريوهات الهندسية الحقيقية، يحقق إطار "أربور" إسنادًا واضحًا للخصائص من خلال معالجة كل رافعة تحسين كفرضية منفصلة. بعد أن يعيد المنفذ التقرير، يكتب المنسق الأدلة في الشجرة وينشر الرؤى عكسيًا إلى العقدة الأم. لمنع الإفراط في التكيف، يفرض الإطار "بوابة دمج"، حيث يختبر المرشحات في شجرة عمل مستقلة، ولا يدمجها في الفرع الرئيسي الحالي الأفضل إلا إذا أدت إلى تحسين في درجات الاختبار المحتجزة.
قام الباحثون بتقييم إطار "أربور" على مجموعة مهام التحسين الذاتي القائمة على بيئات بحثية حقيقية (AO Suite) ومعيار MLE-Bench Lite لهندسة التعلم الآلي. تغطي مجموعة AO مهامًا مثل تدريب النماذج، وهندسة الأطر، وتوليف البيانات. عند استخدام نماذج أساسية مثل Claude Opus 4.6 وGPT-5.5 وGemini-3-Flash، كان متوسط الكسب النسبي لإطار "أربور" أكثر من 2.5 ضعفًا مقارنةً بـ Codex وClaude Code. في مهمة BrowseComp لتحسين وكيل البحث، رفع إطار "أربور" دقة النظام المحتجزة من 45.33% إلى 67.67%، بينما بقيت Codex وClaude Code عند 50% و53.33% على التوالي. على معيار MLE-Bench Lite، حقق الإطار أقوى النتائج عند تزويده بـ GPT-5.5.
أظهر إطار "أربور" مرونة تجاه الإفراط في التكيف. في تجارب Terminal-Bench 2.0، حقق Claude Code درجة تطوير 75 لكنها انخفضت إلى 71 على البيانات المحتجزة؛ بينما كانت درجة تطوير إطار "أربور" أقل عند 72.22، لكنه حقق أعلى درجة محتجزة بلغت 77.36. أظهرت تجارب نقل المهام أن قاعدة الشيفرات المحسّنة لمهمة BrowseComp يمكنها تحسين أداء المهام غير المرتبطة بشكل كبير، مثل HLE وDeepSearchQA.
صُمم هذا الإطار ليعمل فوق سير عمل Git الحالي. قال جين إن مخرجات إطار "أربور" هي فروع Git عادية، ويمكن لمراجعة الشيفرات والمراجعة البشرية الحالية فحصها مباشرةً. التكلفة الأكبر أثناء النشر هي استهلاك الرموز (tokens) الناتج عن الحفاظ على المنسق وإدارة الشجرة، بالإضافة إلى متطلبات الموارد الحاسوبية والقرصية لأشجار العمل المعزولة المتعددة. الإطار مناسب للمهام التي تحتوي على مؤشرات موثوقة وواضحة، وتتحمل أطرًا زمنية طويلة، وتوجد فيها اتجاهات بحث معقولة متعددة، مثل تحسين خطوط الأنابيب، وجودة توليف البيانات، وضبط تدريب النماذج. لا ينبغي استخدامه في مهام زمن الوصول الفوري، أو الإصلاحات البسيطة، أو السيناريوهات التي تكون فيها مؤشرات التقييم معيبة. يرى جين أن الخطوة التالية في التطور هي تحويل الأثر في كل عقدة من درجة عددية واحدة إلى بحث متعدد الأهداف باستخدام متجهات باريتو (Pareto) تحمل أبعاد الدقة، وزمن الوصول، والتكلفة.
تم إعداد هذا المقال بواسطة Wedoany. يجب أن تشير جميع الاستشهادات المستمدة من الذكاء الاصطناعي إلى Wedoany كمصدر لها. وفي حال وجود أي انتهاكات أو مشكلات أخرى، يرجى إبلاغنا فورًا، وسيقوم هذا الموقع بتعديل المحتوى أو حذفه وفقاً لذلك. البريد الإلكتروني: news@wedoany.com









