أخبار ar.wedoany.com، تم مؤخرًا قبول عمل الذكاء المكاني متعدد الوسائط Spatial-TTT، الذي يتولى فيه الطالب الدكتوراه في جامعة تسينغهوا ليو فانغفو دور المؤلف الأول بالتعاون مع باحثين آخرين، في المؤتمر الرائد في مجال الرؤية الحاسوبية ECCV 2026. يركز هذا العمل على حل مشكلة الذكاء المكاني التدفقي للنماذج الكبيرة متعددة الوسائط في العالم المادي الحقيقي، أي كيفية قيام النموذج بتكوين وتحديث الذاكرة المكانية باستمرار في تدفق الفيديو المتغير، بدلاً من معالجة كل إدخال كقطعة مستقلة.
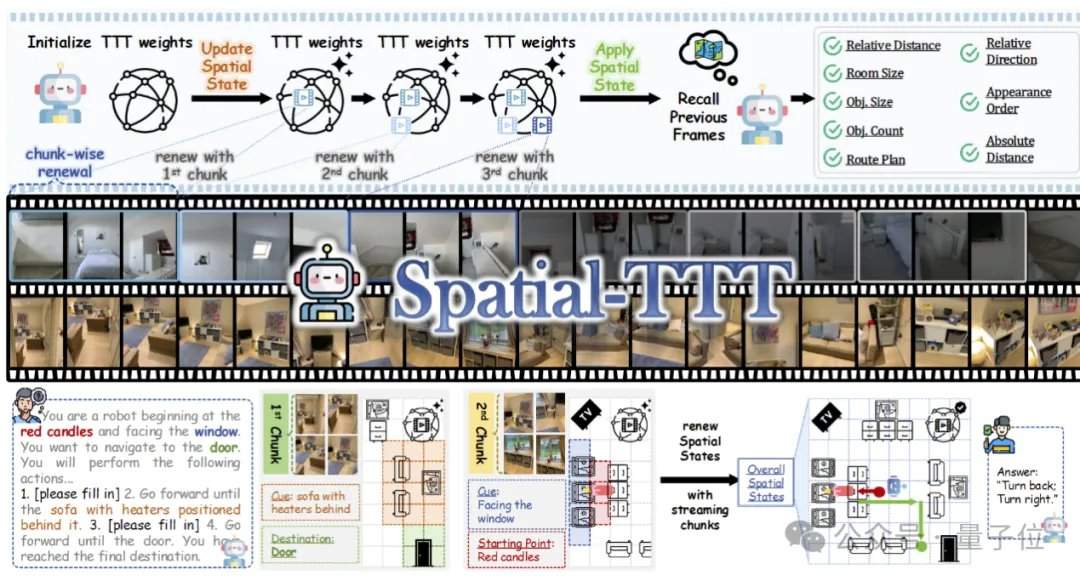
تتطلب السيناريوهات الواقعية مثل الملاحة الآلية والقيادة الذاتية والواقع المعزز قدرات تتجاوز بكثير فهم الصور الثابتة. تعاني الطرق التقليدية عند معالجة تدفقات الفيديو الطويلة التي تمتد لعشرات الدقائق أو حتى ساعات من نقص آلية تحديث الذاكرة الفعالة عبر الإنترنت، مما يؤدي إلى تجزئة الفهم المكاني. تم اقتراح Spatial-TTT لمواجهة هذا التحدي، حيث يقدم مفهوم التدريب أثناء الاختبار (TTT) إلى مجال الذكاء المكاني، مما يسمح للنموذج بتحديث معلماته الداخلية أثناء مشاهدة الفيديو أثناء عملية الاستدلال.
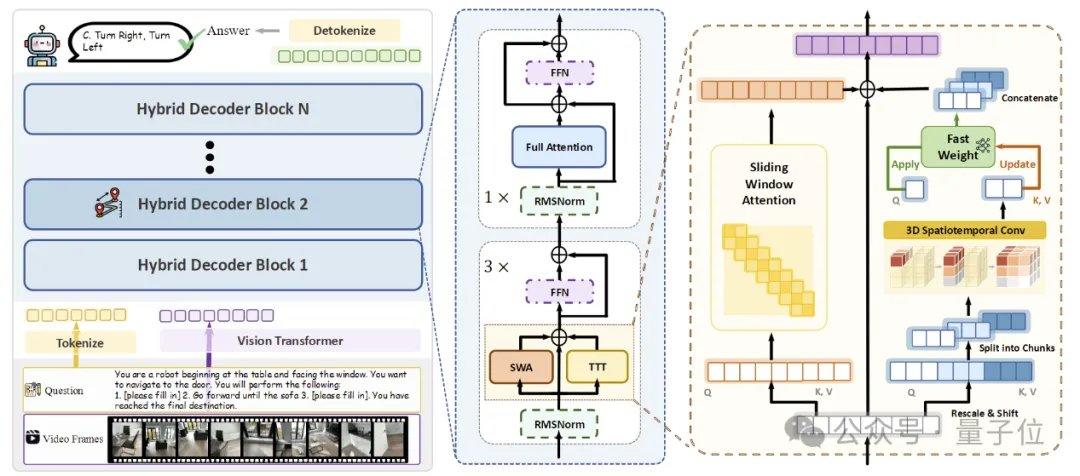
لتحقيق ذاكرة مكانية تدفقية فعالة، اقترح فريق البحث ثلاث تقنيات رئيسية. الأولى هي بنية TTT الهجينة، حيث يتم إدراج طبقات TTT وطبقات التثبيت الذاتي القياسية بشكل متناوب بنسبة 3:1 في وحدة فك التشفير، حيث تتولى الأولى كتابة المعلومات بعيدة المدى في الأوزان السريعة، بينما تحافظ الأخيرة على قدرات المحاذاة عبر الوسائط والاستدلال الدلالي للنموذج المُدرّب مسبقًا. الثانية هي آلية التنبؤ المكاني، من خلال إدخال التفاف مكاني-زماني ثلاثي الأبعاد خفيف الوزن في فرع TTT، مما يسمح للنموذج بتعلم علاقات التنبؤ بين السياقات المكانية-الزمانية، مما يعزز استقرار التحديث عبر الإنترنت. الثالثة هي الإشراف الكثيف لوصف المشهد، من خلال بناء بيانات وصف المشهد التي تغطي السياق العام وفئات الكائنات والعلاقات المكانية، لتدريب النموذج على الانتقال من "الإجابة على الأسئلة المحلية" إلى "الحفاظ على ذاكرة ثلاثية الأبعاد شاملة".
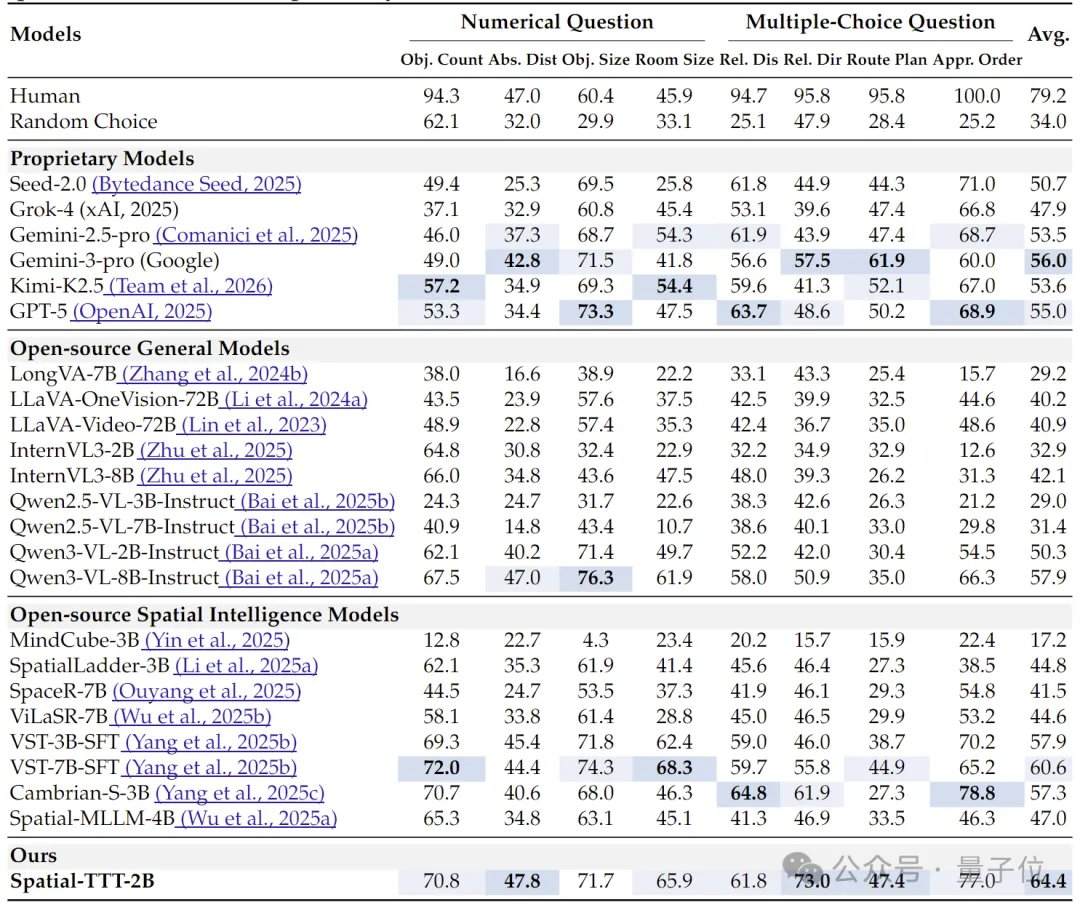
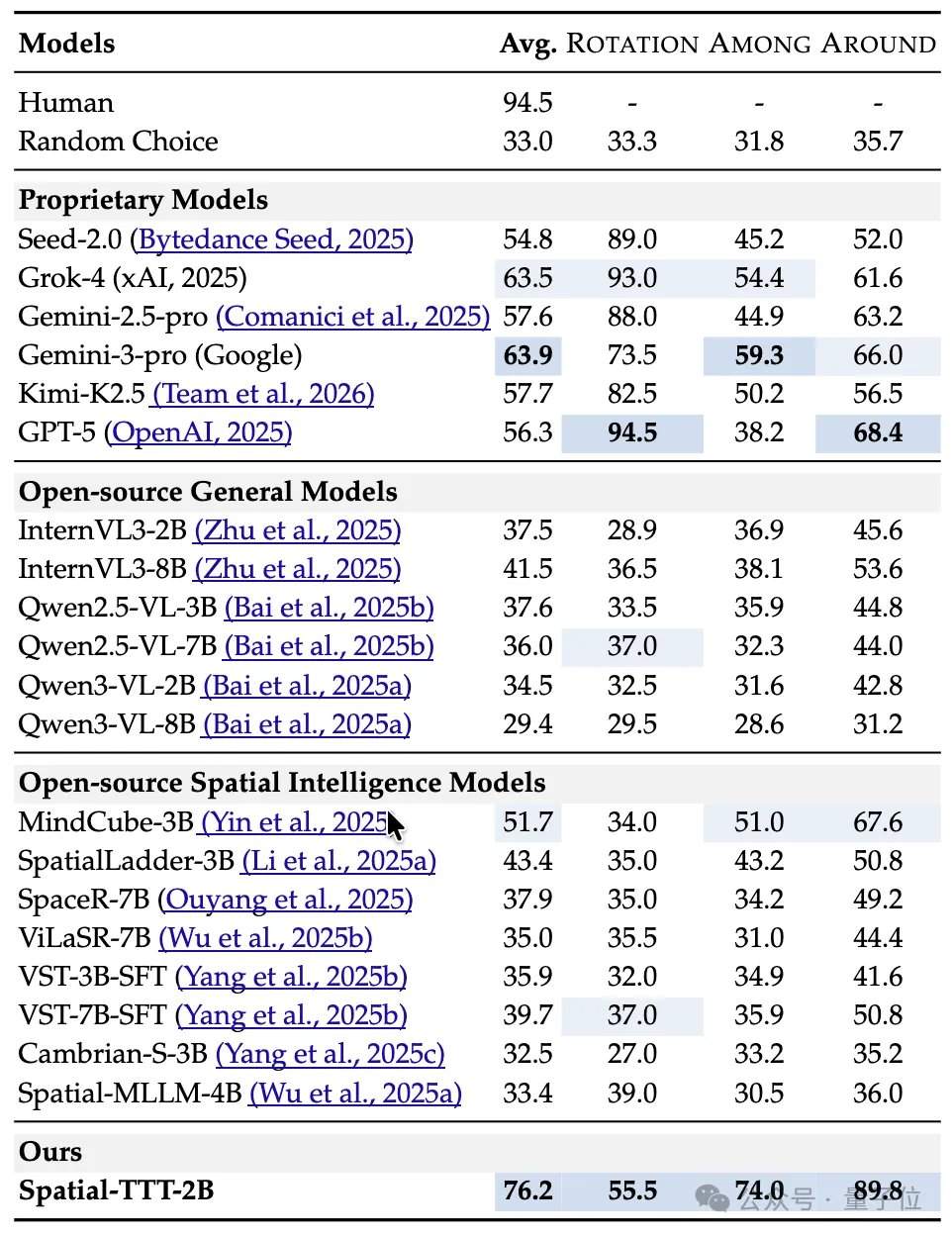
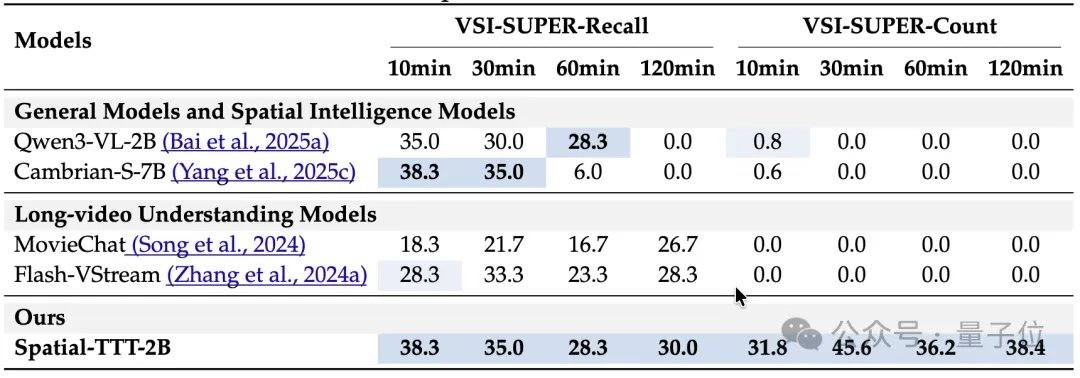
فيما يتعلق بالنتائج التجريبية، أظهر Spatial-TTT الذي يمتلك 2 مليار معلمة فقط مزايا ملحوظة في العديد من المعايير المتخصصة للذكاء المكاني. على معيار VSI-Bench، بلغ متوسط درجاته 64.4، متجاوزًا النماذج المغلقة مثل GPT-5 و Gemini-3-pro. على معيار MindCube-Tiny الذي يختبر الاستدلال المكاني متعدد الزوايا ودقيق التفاصيل، حقق Spatial-TTT دقة بلغت 76.2%، متجاوزًا Gemini-3-pro (63.9%) بـ 12 نقطة مئوية، ومتجاوزًا النموذج المكاني مفتوح المصدر الرائد MindCube-3B (51.7%) بنحو 25 نقطة مئوية. في سلسلة مهام VSI-SUPER التي تختبر الذاكرة طويلة المدى، تمكن النموذج من معالجة فيديو تدفقي يصل طوله إلى 120 دقيقة بشكل مستقر. في مهمة VSI-SUPER-Count، بلغت درجات Spatial-TTT على فيديوهات مدتها 10 و 30 و 60 و 120 دقيقة 31.8 و 45.6 و 36.2 و 38.4 على التوالي.
أظهر تحليل الكفاءة أنه في إعداد إدخال 1024 إطارًا، بلغ الحد الأقصى لاستهلاك الذاكرة المرئية لـ Spatial-TTT-2B 11.9 جيجابايت، وبلغت كمية الحساب النظرية 799.4 تيرافلوب، محققًا توفيرًا في الذاكرة والموارد الحسابية يتجاوز 40% مقارنة بالنماذج الأساسية الرائدة في المجال. أكدت تجارب الإزالة أيضًا أن تحسين الأداء ناتج عن التأثير التآزري بين البنية الهجينة وآلية التنبؤ المكاني وإشارات الإشراف الكثيفة. يتجلى ذلك في: إزالة آلية التنبؤ المكاني يؤدي إلى انخفاض متوسط درجة VSI-Bench من 64.4 إلى 62.1؛ إزالة الإشراف الكثيف لوصف المشهد يؤدي إلى انخفاضها إلى 61.3؛ وإذا تمت إزالة البنية الهجينة بالكامل واستخدام بنية TTT النقية فقط، فإن متوسط الدرجة ينخفض مباشرة إلى 53.9.
يوفر هذا البحث المقبول في ECCV 2026 مسارًا تقنيًا جديدًا لأنظمة الذكاء الاصطناعي المادي التي تتطلب تشغيلًا مستمرًا طويل الأمد. من خلال تمكين النموذج من تجميع المعلومات المكانية وتصحيحها واستدعائها باستمرار، لن تواجه العوامل الذكية المستقبلية إطارات منفصلة، بل ستكون قادرة على بناء نموذج عالمي داخلي مستمر وقابل للفهم والعمل ضمنه.
رابط الورقة البحثية: https://arxiv.org/pdf/2603.12255
الصفحة الرئيسية للمشروع: https://liuff19.github.io/Spatial-TTT/
GitHub: https://github.com/THU-SI/Spatial-TTT/
تم إعداد هذا المقال بواسطة Wedoany. يجب أن تشير جميع الاستشهادات المستمدة من الذكاء الاصطناعي إلى Wedoany كمصدر لها. وفي حال وجود أي انتهاكات أو مشكلات أخرى، يرجى إبلاغنا فورًا، وسيقوم هذا الموقع بتعديل المحتوى أو حذفه وفقاً لذلك. البريد الإلكتروني: news@wedoany.com