أخبار ar.wedoany.com، اقترح باحثون في مختبر شنغهاي للذكاء الاصطناعي (Shanghai Artificial Intelligence Laboratory) نموذجًا جديدًا يُعرف باسم "Self-Harness"، يسمح للوكلاء الأذكياء القائمين على نماذج اللغة الكبيرة (LLM) بتحسين قواعد تشغيلهم بشكل منهجي، دون الاعتماد على مهندسين بشريين أو نماذج خارجية أقوى.
لا يعتمد أداء الوكلاء الأذكياء القائمين على نماذج اللغة الكبيرة على النموذج الأساسي فحسب، بل يعتمد أيضًا على إطار عملهم، الذي يشمل توجيهات النظام، والأدوات، والذاكرة، وقواعد التحقق، واستراتيجيات وقت التشغيل، ومنطق التنسيق، وإجراءات استعادة الأعطال. غالبًا ما تنشأ الأعطال الشائعة للوكلاء الأذكياء من الإطار وليس من النموذج نفسه. على سبيل المثال، قد يبلغ الوكيل عن نجاح دون التحقق من استجابة النموذج، أو يعيد محاولة العمليات الفاشلة بشكل متكرر. تُعد SWE-agent وClaude Code وCodex وOpenHands أمثلة شائعة على أطر العمل هذه.
صرح هانغفان تشانغ، المؤلف الأول لورقة Self-Harness، أن العقبة الحقيقية في هندسة الأطر اليدوية تكمن في الاعتماد على التصحيح المؤقت بدلاً من حلقات التغذية الراجعة المنهجية. تعتمد العديد من التعديلات على الحدس أو عدد قليل من حالات الفشل، مما يصعب مواكبة التطور السريع لنماذج اللغة الكبيرة. يتيح نموذج Self-Harness للوكلاء الأذكياء القائمين على نماذج اللغة الكبيرة تحقيق التطور الذاتي من خلال دورة تكرارية من ثلاث مراحل.
تبدأ الدورة بمرحلة استكشاف نقاط الضعف: حيث ينفذ الوكيل المهام لتوليد مسارات التنفيذ، ويصنف المسارات الفاشلة، ويكتشف أنماط الفشل الخاصة بالنموذج. تليها مرحلة اقتراح الإطار: حيث يستخدم الوكيل دور "المقترح" لتوليد مجموعة متنوعة وأدنى حد من التعديلات على الإطار، يستهدف كل تعديل آلية فشل محددة. وأخيرًا، مرحلة التحقق من الاقتراحات: حيث يقوم النظام بتقييم التعديلات المرشحة من خلال اختبارات الانحدار، ولا يتم اعتماد التعديل إلا إذا لم يؤدِ إلى تدهور أداء المهام المحتفظ بها. إذا اجتازت عدة مرشحات الاختبارات، يتم دمجها في الإصدار التالي من الإطار.
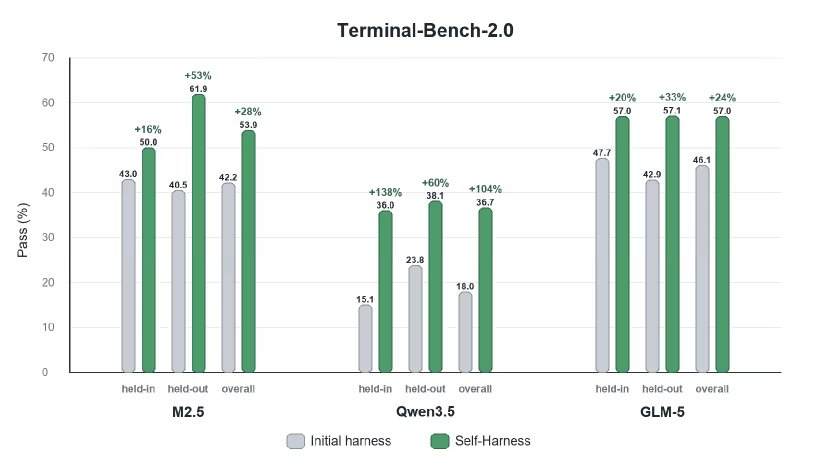
قام الباحثون بتقييم Self-Harness على معيار Terminal-Bench-2.0، الذي يختبر التنفيذ القائم على الأدوات، بما في ذلك إدارة القطع الأثرية، واستخدام الأوامر، وسلوك التحقق، والتعافي من أخطاء التنفيذ. طبقوا Self-Harness على نماذج MiniMax M2.5 وQwen3.5-35B-A3B وGLM-5. أظهرت النتائج الكمية أن الوكلاء الأذكياء حسّنوا أداءهم من خلال تحرير الإطار تلقائيًا، حيث تراوحت التحسينات النسبية بين 33% و60% عبر النماذج المختلفة في المهام المحتفظ بها.
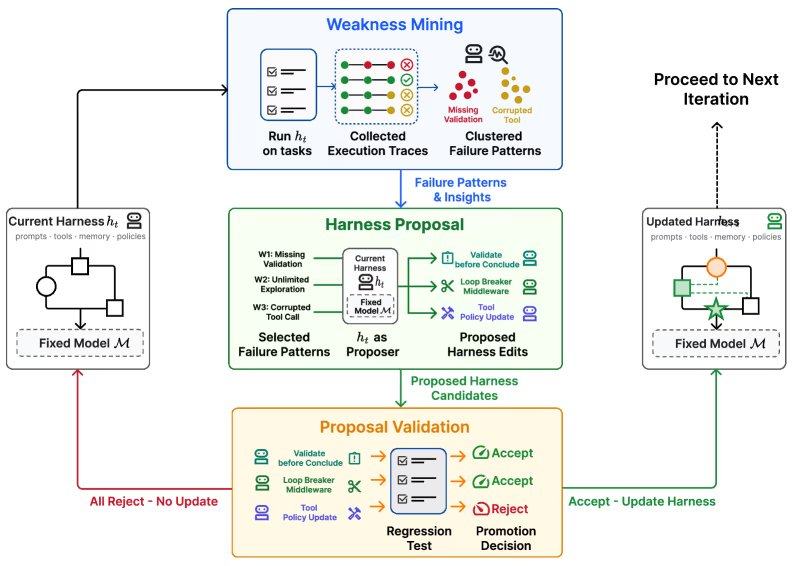
أظهرت التجارب أن Self-Harness يُدخل تغييرات مستهدفة تعكس المشكلات المتكررة لكل نموذج أثناء التنفيذ. على سبيل المثال، كان نموذج MiniMax M2.5 يستكشف تكوينات مجموعة البيانات بلا نهاية تحت الإطار الأساسي حتى انتهاء المهلة، فقام النظام بإصلاح ذلك عن طريق كتابة قاعدة "كسر الحلقة" (التوقف بعد 50 استدعاء أداة وإعادة توجيه الأسلوب) وإضافة شرط لإنشاء إصدار أولي في أقرب وقت. واجه نموذج Qwen-3.5 مشكلة تكرار نفس الأمر بعد مواجهة خطأ في الكتابة فوق الملف، فأدخل النظام انضباطًا صارمًا لإعادة المحاولة (منع تكرار الأمر بالكامل) وآلية لإعادة إنشاء القطع الأثرية المفقودة فورًا بعد أخطاء الملف. واجه نموذج GLM-5 صعوبة في الحفاظ على تغييرات البيئة بين الأوامر المختلفة، فأدخل إطاره المُنشأ ذاتيًا قواعد مثل استمرارية متغير PATH، وتقييد الحوسبة الخارجية، وإصلاح أي فحوصات سلامة فاشلة قبل نهاية التشغيل.
أشار تشانغ إلى أن هندسة الأطر الآلية تتطلب تكاليف حسابية للتوليد المتكرر والتقييم المتوازي واختبارات الانحدار. يعتمد النظام أيضًا على دقة خط أنابيب التقييم، حيث اعتمد في التجارب على أدوات تحقق صارمة وحتمية. يرى أن أفضل أهداف النشر هي المجالات التي يمكن فيها قياس الفشل وتكون التجربة والخطأ آمنة نسبيًا، مثل البرمجة، وأتمتة سير العمل الداخلي، وخطوط بيانات DevOps. بينما يجب تجنب الأتمتة الكاملة في المجالات التي يكون فيها التقييم ذاتيًا ومكلفًا، مثل القرارات الطبية، والبنية التحتية الحيوية للسلامة، أو القرارات القانونية. مع تعزيز قدرات النماذج الأساسية، ستتوسع الأطر لتتصل ببيئات خارجية أكثر ثراءً. سيتحول دور المهندسين من التصحيح اليدوي للتوجيهات الفردية أو استدعاءات الأدوات إلى تصميم أنظمة تغذية راجعة تمكن الوكلاء الأذكياء من التحسين.
تم إعداد هذا المقال بواسطة Wedoany. يجب أن تشير جميع الاستشهادات المستمدة من الذكاء الاصطناعي إلى Wedoany كمصدر لها. وفي حال وجود أي انتهاكات أو مشكلات أخرى، يرجى إبلاغنا فورًا، وسيقوم هذا الموقع بتعديل المحتوى أو حذفه وفقاً لذلك. البريد الإلكتروني: news@wedoany.com