أخبار ar.wedoany.com، تم إطلاق نموذج AudioX-Turbo فائق السرعة لتوليد الصوت، حيث ينتج 10 ثوانٍ من الصوت في 0.24 ثانية بأربع خطوات استدلال. طورته شركة Noiz AI بالتعاون مع جامعة هونغ كونغ للعلوم والتكنولوجيا وجامعة تسينغهوا، ويدعم النموذج إدخالات متعددة الوسائط مثل النصوص والفيديو والصور. من خلال تقنيات تقطير مطابقة التوزيع وتقطير المواجهة، تم ضغط عملية التوليد التقليدية لنماذج الانتشار من 50 إلى 200 خطوة إلى 4 خطوات فقط، مما يقلل عدد مرات تمرير النموذج الأمامي بنحو 25 مرة. على بطاقة رسوميات واحدة من نوع RTX 4090، يستغرق توليد 10 ثوانٍ من الصوت 0.24 ثانية فقط، بعامل زمني فوري يبلغ 0.02، مما يفتح آفاقًا للتفاعل الصوتي في الوقت الفعلي.
تعتمد النماذج الصوتية الرئيسية الحالية مثل MMAudio وStable Audio Open على تقنيات الانتشار أو مطابقة التدفق، وتتطلب عادةً عشرات إلى مئات التكرارات. يستخدم AudioX-Turbo محول الانتشار متعدد الوسائط (MMDiT) المدمج أصلاً كبنية أساسية، إلى جانب وحدة MAF، وتم تدريبه من الصفر بمعاملات تبلغ 2.7 مليار. في إطار مطابقة التدفق، أدخل فريق البحث تقطير مطابقة التوزيع (DMD) وتقطير المواجهة لضغط النموذج إلى 4 خطوات، مع إزالة النفقات الحسابية الإضافية لـ CFG من خلال تقطير CFG. بفضل المميِّز الانتشار، تفوق النموذج الطالب على النموذج المعلم ذي الـ 100 خطوة في بعض مؤشرات الأداء.
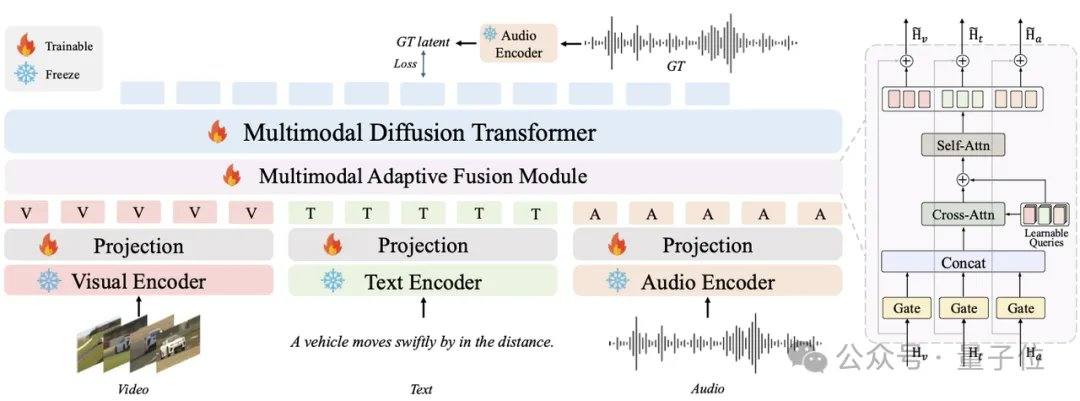
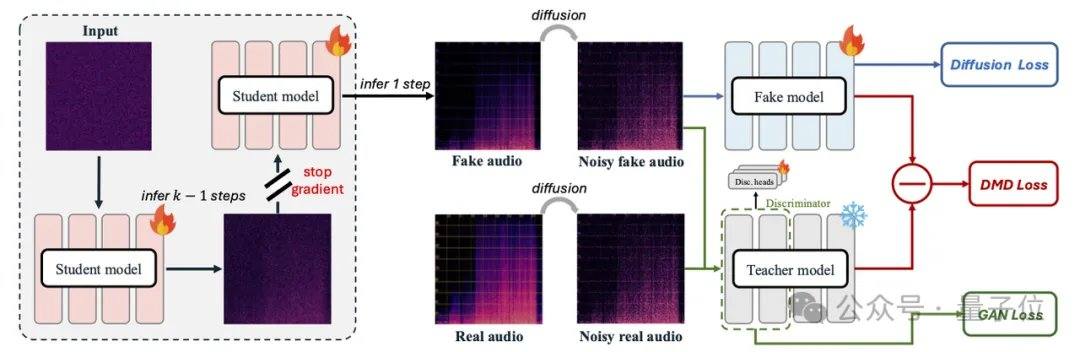
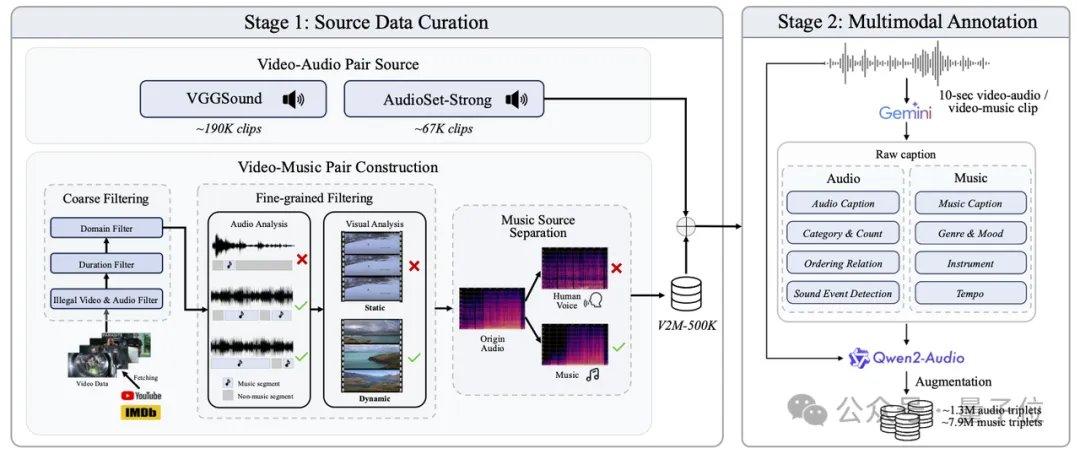
عالج AudioX-Turbo أيضًا مشكلة صعوبة التحكم الدقيق في النماذج الصوتية. أشار فريق البحث إلى أن العديد من النماذج السابقة لم تكن قادرة على التحكم بدقة في الطوابع الزمنية، ويعود السبب الجذري إلى غموض تسميات النصوص في بيانات التدريب. لهذا، قامت Noiz AI وفريق جامعة هونغ كونغ للعلوم والتكنولوجيا ببناء مجموعة بيانات صوتية متعددة الوسائط فائقة الحجم باسم IF-caps-Pro، يبلغ إجمالي حجمها حوالي 9.2 مليون عينة. اعتمد الفريق نهج "التوسيم المتسلسل للنماذج الكبيرة"، حيث قام أولاً ببناء أزواج فيديو-صوت عالية الجودة على نطاق واسع، ثم استخدم نموذج Gemini 2.5 Pro لتوليد قوالب منظمة تحتوي على طوابع زمنية وآلات وأعداد الأحداث، ثم استخدم Qwen2-Audio للتوسيع على نطاق واسع، مما حوّل البيانات من "ملخصات غامضة" إلى "نصوص ذات محاور زمنية دقيقة".
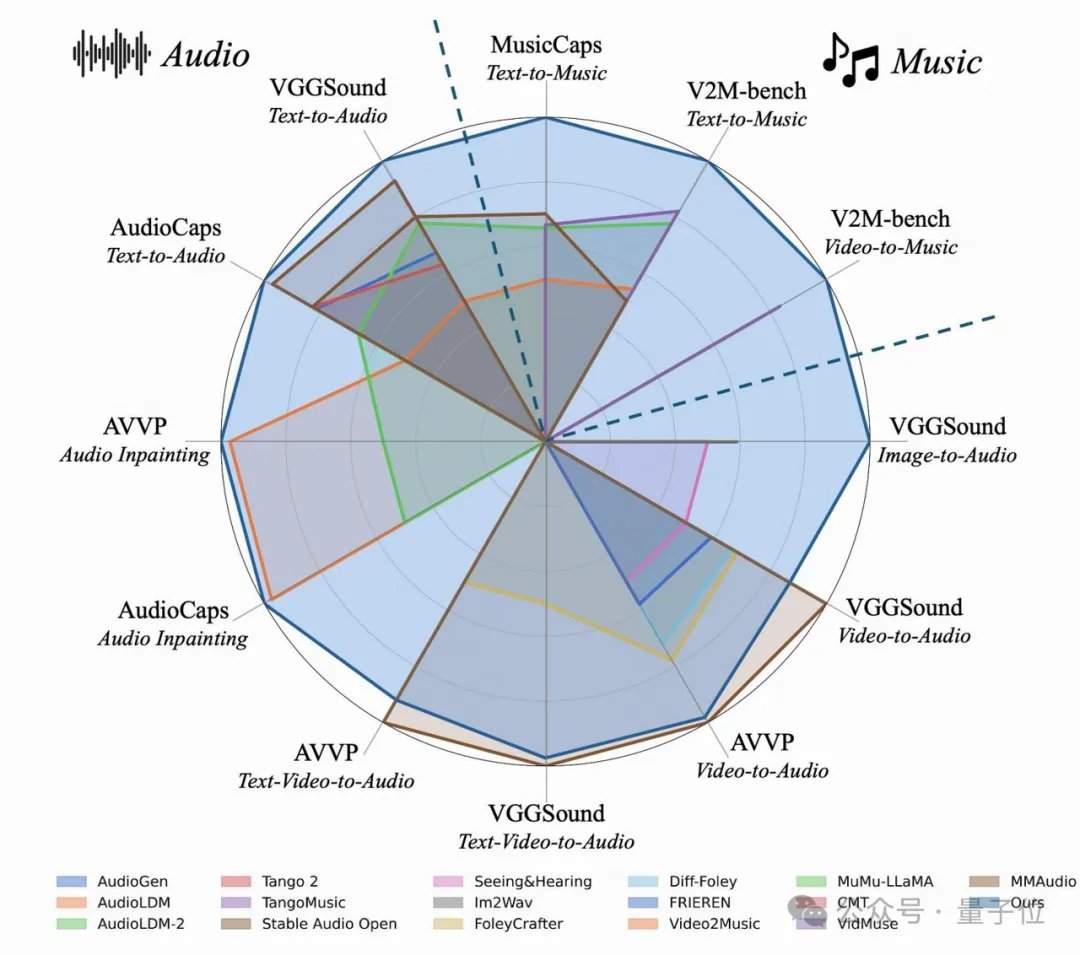
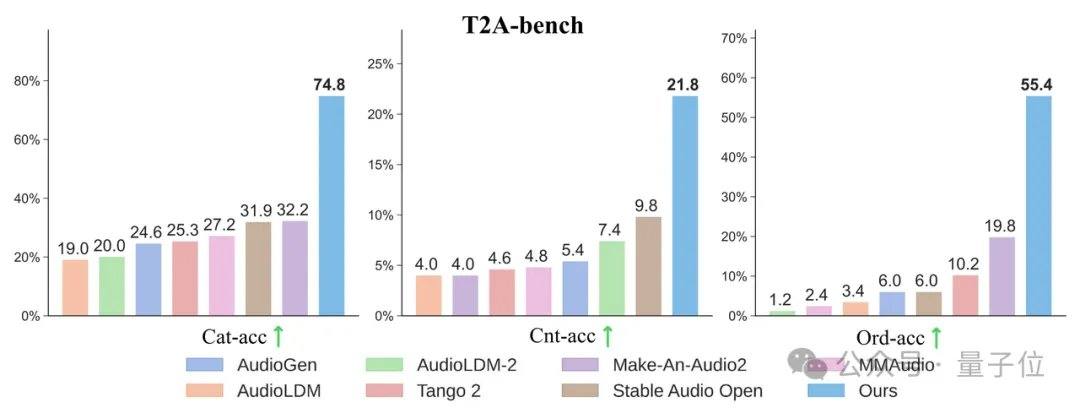
اكتشف فريق البحث بشكل غير متوقع أنه كلما كانت تسميات النصوص أكثر تفصيلاً، لم يتحسن أداء النموذج في توليد الصوت من النص فحسب، بل تحسنت أيضًا درجة التوافق عند "مزامنة الصوت مع الفيديو الصامت" بشكل كبير. في مجموعات الاختبار الكلاسيكية مثل AudioCaps وMusicCaps، تفوق نموذج AudioX-Turbo ذو الـ 4 خطوات على العديد من النماذج الأساسية التي تتطلب 50 إلى 200 خطوة في مؤشرات جودة الصوت الأساسية، أو تعادل أداءها. لتقييم قدرة اتباع التعليمات، بنى الفريق معيارًا خاصًا باسم T2A-bench، وفي التقييمات التي تركز على فئات الأصوات وعددها وطوابعها الزمنية وترتيبها، أظهر AudioX-Turbo أداءً ساحقًا مقارنة بالطرق الأساسية الأخرى، حيث تجاوزت بعض المؤشرات ضعف أداء الخط الأساسي.
تشمل أبرز ثلاث ميزات لـ AudioX-Turbo: الاستدلال بأربع خطوات، مما يقلل الحساب بمقدار 25 مرة مقارنة بالنموذج المعلم مع أداء أفضل، وعامل زمني فوري يبلغ 0.02 فقط؛ مجموعة بيانات قوية تحتوي على 9.2 مليون تعليمة، مما يحقق التحكم الدقيق في الطوابع الزمنية لأول مرة؛ دعم إدخالات متعددة الوسائط مثل النصوص والفيديو والصور، مما يتيح توليد "أي شيء إلى صوت". تم فتح جميع أكواد التدريب وأوزان النموذج بالكامل كمصدر مفتوح. الورقة البحثية بعنوان "AudioX-Turbo: A Unified Framework for Efficient Anything-to-Audio Generation"، وقد أنجزها فريق من Noiz AI وجامعة هونغ كونغ للعلوم والتكنولوجيا وجامعة تسينغهوا، والصفحة الرئيسية للمشروع هي https://zeyuet.github.io/AudioX-Turbo/.
تم إعداد هذا المقال بواسطة Wedoany. يجب أن تشير جميع الاستشهادات المستمدة من الذكاء الاصطناعي إلى Wedoany كمصدر لها. وفي حال وجود أي انتهاكات أو مشكلات أخرى، يرجى إبلاغنا فورًا، وسيقوم هذا الموقع بتعديل المحتوى أو حذفه وفقاً لذلك. البريد الإلكتروني: news@wedoany.com