
أخبار ar.wedoany.com، أطلقت شركة بايدو في 22 يونيو نموذج "Unlimited OCR" مفتوح المصدر، بهدف حل مشكلة التباطؤ التدريجي في نماذج OCR الشاملة عند تحليل المستندات الطويلة. يبلغ إجمالي عدد معلمات هذا النموذج 3 مليارات، بينما يتم تنشيط 500 مليون معلمة فقط أثناء الاستدلال.
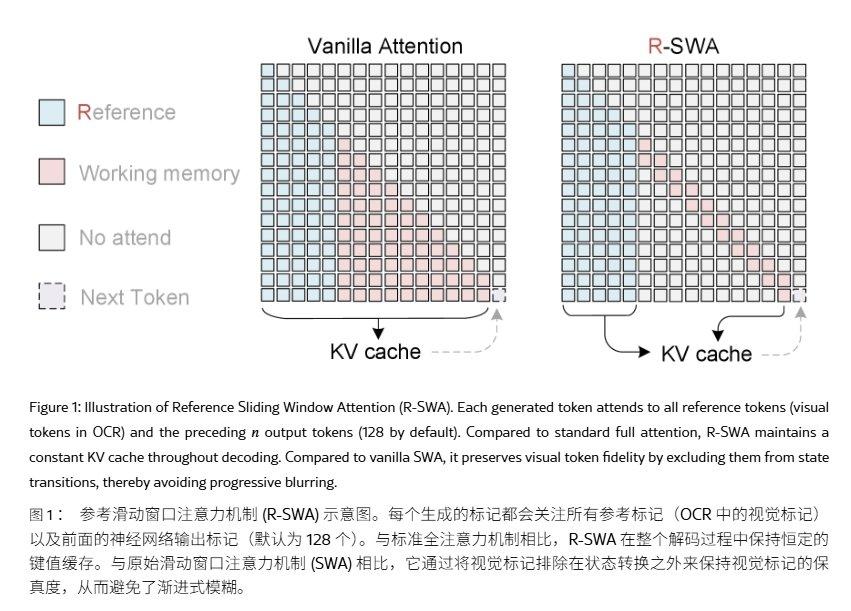
تعتمد نماذج OCR الشاملة على بنية شبكة عصبية موحدة، حيث تدمج اكتشاف النص والتعرف على الأحرف في نظام واحد، وتقوم بتعيين الصورة المدخلة مباشرة إلى تسلسل نصي مخرج، متخلية عن العملية التقليدية التي تتضمن أولاً اكتشاف مربعات النص ثم التعرف عليها بشكل منفصل. في النماذج الرئيسية للـ OCR الشامل، يؤدي توليد كل رمز (token) إلى توسيع ذاكرة التخزين المؤقت للمفاتيح والقيم (KV cache)، مما يتسبب في زيادة مستمرة في استهلاك الذاكرة وزمن الاستجابة، ويشعر المستخدم بتباطؤ تحليل المستندات متعددة الصفحات كلما تقدم التحليل.
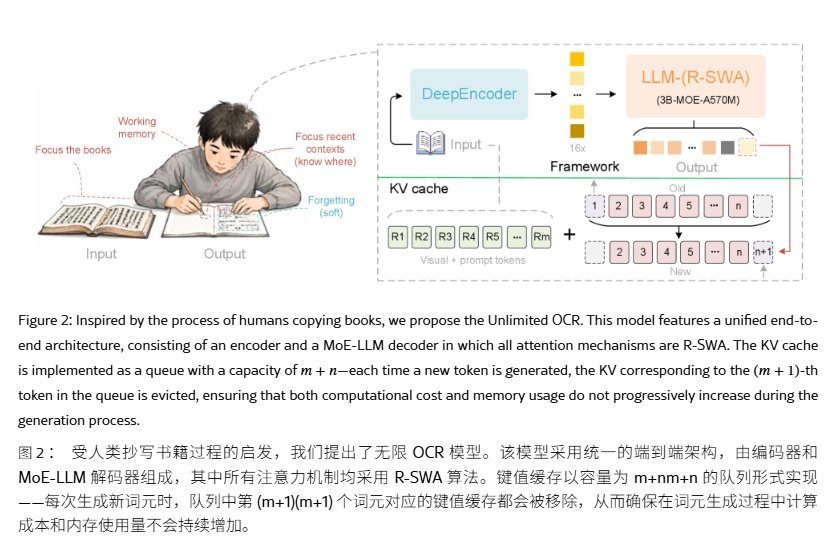
يحافظ نموذج Unlimited OCR على بنية DeepSeek OCR، مع الاحتفاظ بـ DeepEncoder ومفكك التشفير الهجين الخبير (MoE). يستخدم جانب التشفير تشفيرًا بصريًا ثنائي المستوى، ويقوم بضغط الرموز (tokens) بمعدل 16 ضعفًا في مرحلة الربط، مما يقلص صورة PDF بحجم 1024×1024 بكسل إلى 256 رمزًا بصريًا، مما يخفف عبء التعبئة المسبقة من المصدر.
فيما يتعلق بالتدريب، تم تدريب نموذج Unlimited OCR لمدة 4000 خطوة إضافية استنادًا إلى نقطة تفتيش DeepSeek OCR، مع تجميد DeepEncoder وتدريب مفكك التشفير فقط. تتكون بيانات التدريب من حوالي 2 مليون عينة مستندية، وتم تشغيلها على 8 وحدات GPU من طراز A16×800. تبلغ نسبة توزيع البيانات بين الصفحات المفردة والمتعددة حوالي 9:1، حيث تم إنشاء عينات الصفحات المتعددة من خلال الربط.
أظهرت الاختبارات المعيارية أن نموذج Unlimited OCR حصل على درجة إجمالية قدرها 93.23 على معيار OmniDocBench v1.5، متجاوزًا DeepSeek OCR الذي حصل على 87.01 وDeepSeek OCR 2 الذي حصل على 89.17. بلغت مسافة التحرير النصية 0.038، ودرجة CDM للصيغ 92.61، ودرجة TEDS للجداول 90.93، ومسافة التحرير لترتيب القراءة 0.045. على معيار OmniDocBench v1.6، وصلت الدرجة الإجمالية للنموذج إلى 93.92.

تم إعداد هذا المقال بواسطة Wedoany. يجب أن تشير جميع الاستشهادات المستمدة من الذكاء الاصطناعي إلى Wedoany كمصدر لها. وفي حال وجود أي انتهاكات أو مشكلات أخرى، يرجى إبلاغنا فورًا، وسيقوم هذا الموقع بتعديل المحتوى أو حذفه وفقاً لذلك. البريد الإلكتروني: news@wedoany.com










