أخبار ar.wedoany.com، تمكنت مجموعة برامج الاستدلال من إنفيديا (NVIDIA) على منصتها Blackwell من خفض تكلفة كل رمز (Token) لنموذج DeepSeek V4 بنسبة تصل إلى 80% (أي إلى الخُمس) خلال شهر واحد. مع انتقال المؤسسات من مرحلة التجارب في الذكاء الاصطناعي إلى مصانع الذكاء الاصطناعي الإنتاجية، تحولت قرارات البنية التحتية من التركيز على مواصفات رقاقات الذروة إلى التركيز على تكلفة كل رمز (Token)، أي عدد الرموز المفيدة المنتجة لكل دولار وكل واط من الطاقة مع الالتزام بأهداف زمن الاستجابة. تعمل مجموعة برامج الاستدلال من إنفيديا بتصميم متكامل مع وحدات معالجة الرسوميات (GPU) ووحدات المعالجة المركزية (CPU) وشبكات وأنظمة NVIDIA، ويتم تعزيز أدائها المستمر من خلال نظام بيئي مفتوح المصدر واسع النطاق.
بدأت الشركات الرائدة ومزودو خدمات الاستدلال في تجربة القيمة المضافة لمجموعة برامج الاستدلال من إنفيديا على منصة Blackwell. تستخدم شركة Baseten مكتبة TensorRT-LLM مفتوحة المصدر من NVIDIA لتقديم خدمة نموذج DeepSeek V4 Pro على وحدات معالجة الرسوميات Blackwell، والمخصص لأعباء عمل الاستدلال والبرمجة والسياقات الطويلة، مما يحقق زيادة في إنتاج الرموز في الثانية تصل إلى 50% من خلال تحسينات وقت التشغيل الخاصة. تستخدم شركة Cognition إطار عمل الاستدلال NVIDIA Dynamo لإدارة وحدات معالجة الرسوميات المخصصة للاستدلال، مما يوفر لفريقها مسارًا جاهزًا لتوسيع نطاق أعباء عمل التعلم المعزز دون الحاجة إلى بناء البنية التحتية من الصفر. تستخدم شركة Deep Infra مجموعة برامج الاستدلال من NVIDIA لتشغيل النماذج مفتوحة المصدر الرائدة عالية الأداء على منصة Blackwell منذ اليوم الأول، بما في ذلك نموذج DeepSeek V4. تستخدم شركة Together AI مكتبة TensorRT-LLM من NVIDIA على منصة Blackwell لمساعدة شركة Cursor في تسريع المسار من تحسين النموذج إلى نقطة النهاية الإنتاجية، لدعم تجربة البرمجة في الوقت الفعلي.
تختلف أعباء عمل الذكاء الاصطناعي الوكيل (Agentic AI) عن أعباء العمل التقليدية لصفحات الويب والبحث والبرمجيات كخدمة، والتي تكون قابلة للتوقع نسبيًا. يمكن للوكيل (Agent) الاستدلال والتخطيط واستدعاء الأدوات وتشغيل وكلاء فرعيين متخصصين وإدارة كميات كبيرة من السياق في سير عمل متعدد الجولات، مما يحول الطلب الفردي إلى مشكلة حوسبة موزعة قد تشمل مئات الوكلاء الفرعيين وآلاف المهام ونماذج لغوية كبيرة متعددة، تعمل على وحدات معالجة الرسوميات (GPU) ووحدات المعالجة المركزية (CPU) ووحدات معالجة البيانات (DPU) وأنظمة تخزين البيانات. تحدد مجموعة البرامج ما إذا كان هذا التعقيد سيتحول إلى طاقة حاسوبية مهدرة أم إلى تكلفة أقل لكل رمز (Token).
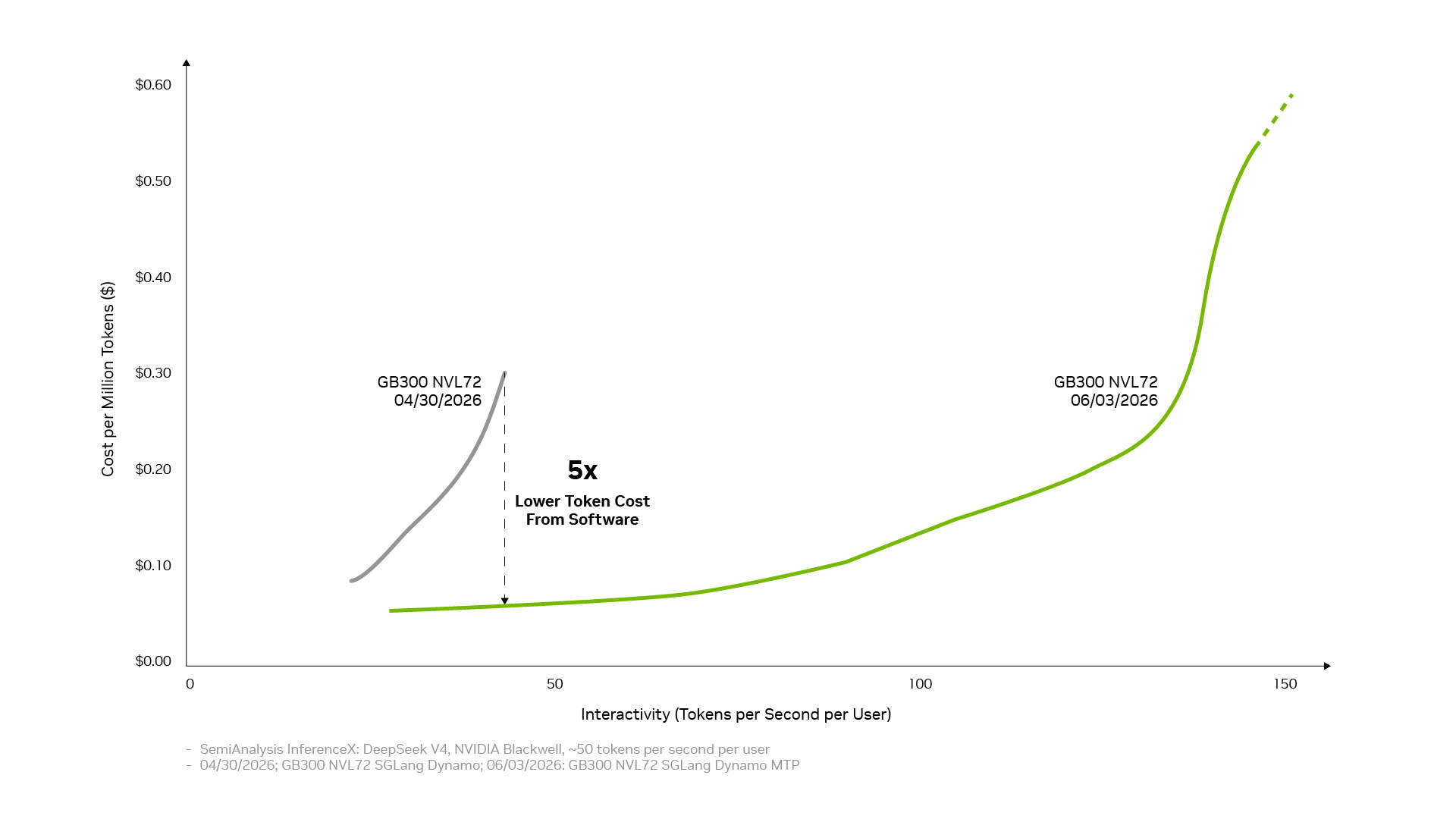
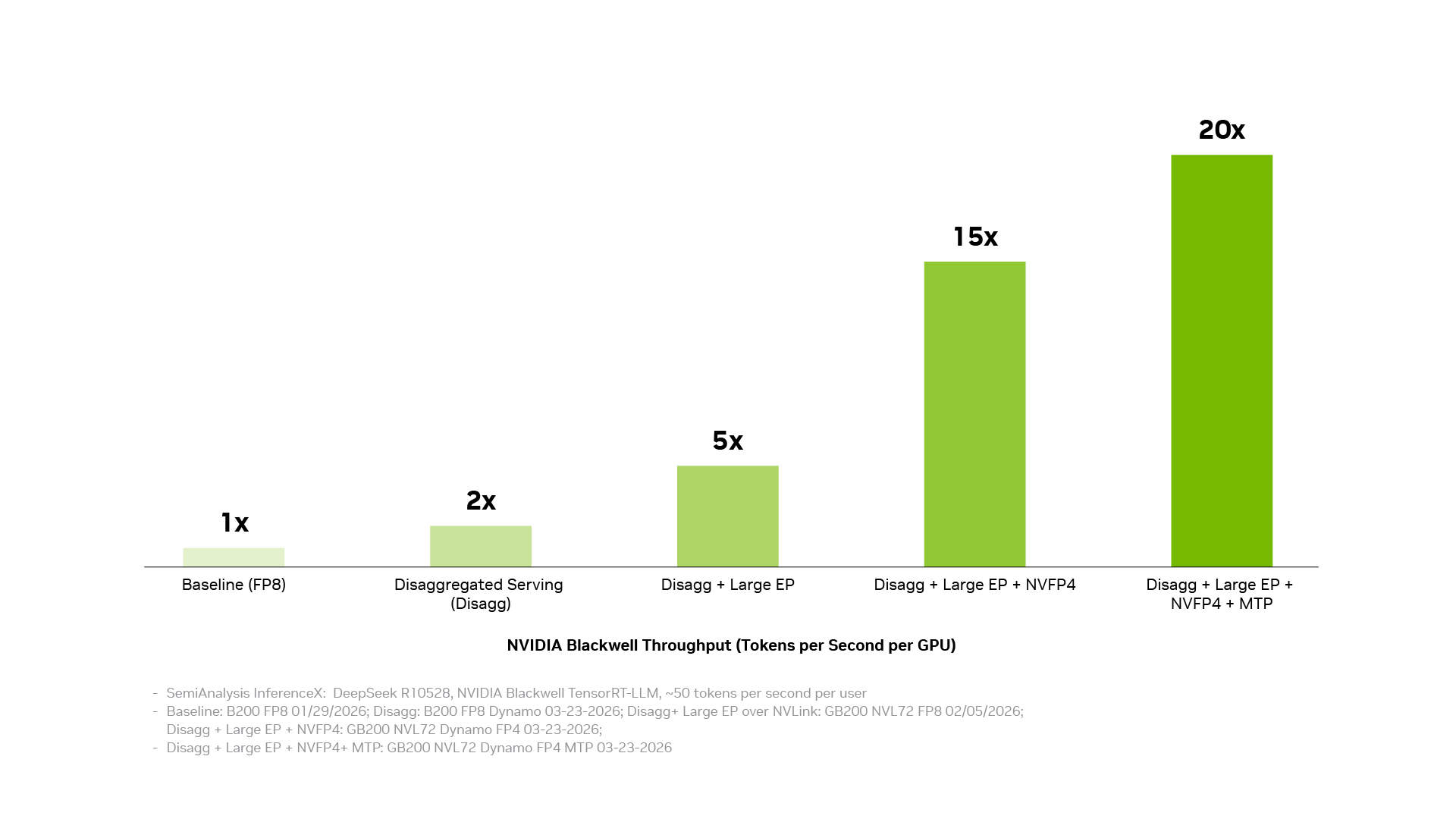
تنشأ تكلفة أقل لكل رمز (Token) من تحويل التحسينات الفردية إلى أداء على مستوى النظام. تحقق مجموعة برامج الاستدلال من إنفيديا ذلك من خلال ربط ثلاث طبقات: طبقة التشغيل والإنتاج التي تنسق الخدمات الموزعة والتنظيم والتوسع التلقائي وإدارة الذاكرة؛ وطبقة تسريع التطبيقات التي تشغل النماذج بأداء عالٍ وتوفر للمطورين مساحة للضبط والتخصيص؛ وطبقة الوصول إلى البنية التحتية التي تتيح إمكانيات وحدات معالجة الرسوميات والشبكات والذاكرة والأنظمة من NVIDIA. عندما تعمل هذه الطبقات معًا كنظام واحد، تتراكم تأثيرات التحسينات الفردية. يؤدي فصل الخدمات، والتوازي الخبير واسع النطاق القائم على تقنية الربط البيني NVIDIA NVLink، ودقة NVFP4، والتنبؤ متعدد الرموز (Multi-Token Prediction) كل منها إلى تحقيق مكاسب كبيرة، وعند دمجها، يمكن أن يزيد الإنتاجية بمقدار يصل إلى 20 ضعفًا.
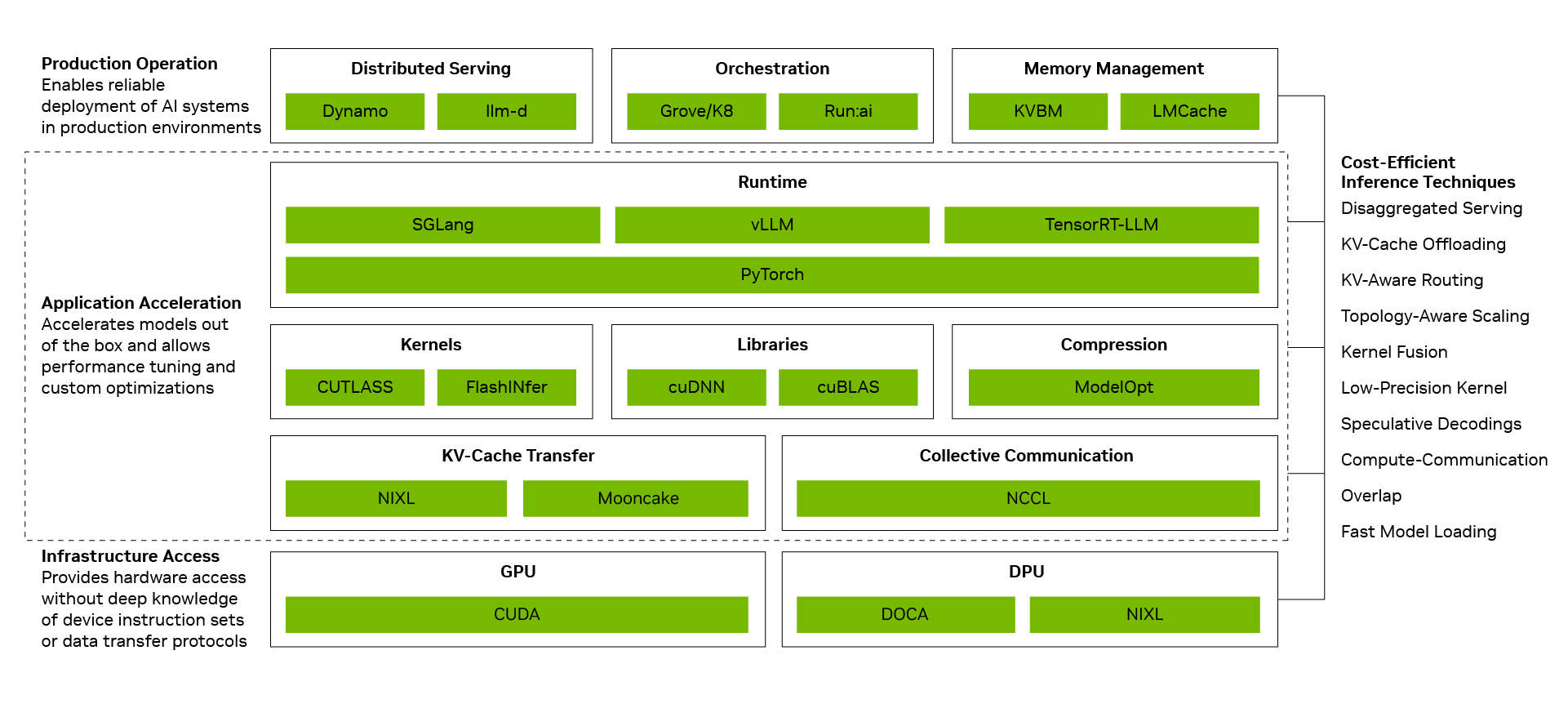
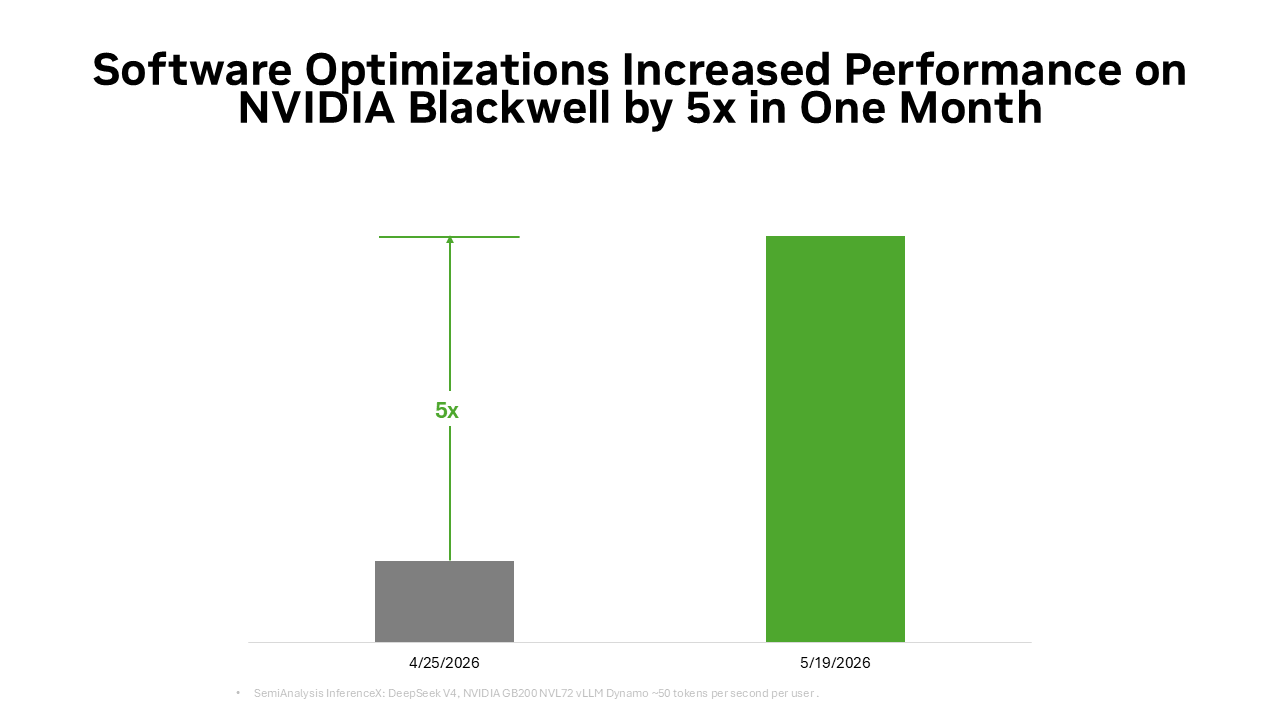
يتم أيضًا تضخيم نفس الأساس الشامل لمجموعة البرامج من خلال النظام البيئي مفتوح المصدر. العديد من أطر وأدوات الذكاء الاصطناعي مفتوحة المصدر المستخدمة على نطاق واسع اليوم مبنية أصلاً على منصة NVIDIA CUDA. يُعد PyTorch مثالًا نموذجيًا، حيث تم إطلاقه في عام 2016 مع دعم أصلي لـ CUDA، وتطور بالتوازي مع بنية NVIDIA. عندما تظهر تقنيات رائدة مثل DFlash Speculative Decoding أو FastVideo على PyTorch، يمكن تشغيلها فورًا على أجهزة NVIDIA. عندما يتم إصدار نماذج مفتوحة المصدر متطورة مثل DeepSeek V4، يمكن لأطر الاستدلال الرائدة مثل vLLM وSGLang توفير حلول نشر لمنصة NVIDIA Blackwell في اليوم الأول. وهذا هو السبب في أن أداء DeepSeek V4 على منصة Blackwell تحسن بمقدار يصل إلى 5 أضعاف خلال شهر واحد من خلال أطر vLLM وSGLang، مما أدى إلى خفض تكلفة كل رمز (Token) إلى حوالي الخُمس.
هذه هي دورة النمو مفتوحة المصدر: كلما زاد عدد المطورين الذين يحسنون مسارات الاستدلال القائمة على CUDA، وكلما زادت عمليات النشر الإنتاجية التي تغذي النظام البيئي، كلما أدى كل تحسين في البرامج إلى زيادة كمية الرموز (Tokens) المنتجة مع خفض تكلفة كل رمز (Token).