
أخبار ar.wedoany.com، شكل الجدل حول المسار التقني لـ تقنيات الروبوتات محورًا رئيسيًا في مؤتمر "ZhiYuan" الذي عُقد في بكين خلال شهر يونيو. على مدار العام الماضي، ومع تصاعد الاهتمام بصناعة الروبوتات، استمر النقاش في الأوساط المتخصصة حول ما إذا كان ينبغي للروبوتات اتباع مسار VLA (الرؤية-اللغة-الفعل) أم مسار النماذج العالمية. قدم الدكتور قوه يان دونغ، المؤسس والرئيس التنفيذي لشركة "ZhiPingFang"، إجابة واضحة في كلمته الافتتاحية بمنتدى الرؤساء التنفيذيين لصناعة الروبوتات المتجسدة ضمن المؤتمر: النماذج العالمية ليست مسارًا منافسًا لـ VLA، بل هي مكون أساسي ضمن منظومتها؛ وبعد دمج النماذج العالمية مع VLA، ستصبح البنى الشبيهة بالدماغ البشري اتجاهًا مهمًا لتطور الجيل القادم من أدمغة الروبوتات.

يأتي هذا التوجه استنادًا إلى الاستثمارات التقنية التي قامت بها "ZhiPingFang" على مدى السنوات الثلاث الماضية. يرى قوه يان دونغ أنه من منظور التطور البيولوجي، لا تنشأ القدرة على الفعل بمعزل عن غيرها؛ فالكائنات الحية تستشعر وتفهم البيئة المحيطة أولاً قبل أن تنتج أفعالاً. أعاد قوه تعريف VLA، معتبرًا إياه تسمية شاملة لبنية نموذجية شاملة من البداية إلى النهاية تعتمد على البيانات الضخمة وتدمج طرائق متعددة، ورأى أنه لا يوجد فرق جوهري بين النماذج العالمية وVLA، كما أنها ليست علاقة استبدال. تحل النماذج العالمية مشكلة التنبؤ الرباعي الأبعاد (4D) الكثيف والمتضمن للبعد الزمني للبيئة المادية، وهي جزء من الإدراك المكاني لـ VLA، وتساعد في تعزيز قدرات دماغ الروبوت. أوضح قوه يان دونغ سبب ضرورة الدمج بينهما بمثال: عملية تحضير الشاي تتطلب أولاً إخراج كيس الشاي ثم صب الماء، وهذه المنطقيات الاستدلالية تعتمد على النموذج اللغوي، بينما النماذج العالمية تجيد التنبؤات قصيرة المدى مثل احتمالية سقوط كوب الماء عند اقترابه من حافة الطاولة، ودمج الاثنين يمكن الروبوت من امتلاك القدرة على التنبؤ الفيزيائي قصير المدى والتخطيط طويل المدى للمهام. تستخدم "ZhiPingFang" أيضًا النماذج العالمية لتوليد بيانات هامشية يصعب جمعها في البيئات الحقيقية، وذلك لتعزيز تدريب VLA.
بناءً على هذا التوجه، أطلقت "ZhiPingFang" في نوفمبر 2025، بالتعاون مع جامعة بكين، البنية الجديدة من الجيل التالي "Video2Act" التي تدمج النماذج العالمية، محققة لأول مرة نموذجًا للروبوتات يقوم على "التنبؤ أولاً، ثم التنفيذ". "Video2Act" ليس نموذجًا تقليديًا لتوليد الفيديو، بل هو بنية VLA تدمج النموذج العالمي رباعي الأبعاد (4D)، حيث تمكن الروبوت من فهم تغيرات الحالة المستقبلية مسبقًا وتحويل القدرة التنبؤية إلى قرارات فعلية، وذلك من خلال نمذجة المعلومات المكانية الكثيفة والإدخال المستمر للتسلسل الزمني للأفعال. في التقييمات التي أجرتها جهات خارجية، حقق "Video2Act" تحسنًا في الأداء يتجاوز 30% مقارنة بأحدث النماذج المماثلة في وادي السيليكون. في الدراسة المرجعية الشاملة حول النماذج العالمية بعنوان "World Model for Robot Learning: A Comprehensive Survey"، والتي شارك في إعدادها نخبة من كبار الباحثين العالميين في مجال الذكاء الاصطناعي، بمن فيهم فيليب تور، زميل الأكاديمية الملكية البريطانية والأكاديمية الملكية للهندسة والباحث العالمي في الذكاء الاصطناعي الحائز على جائزة تورينج، وبيتر أبيل، أحد مؤسسي مجال التعلم المعزز، تم الاستشهاد بـ "Video2Act" كإنجاز بارز يمثل مسار "دمج النماذج العالمية مع VLA".

بعد حل مشكلة دمج النماذج العالمية مع VLA، ركزت "ZhiPingFang" على التحدي المتمثل في تمكين الروبوتات من التصرف بثبات وكفاءة مثل البشر. قدم قوه يان دونغ في مؤتمر "ZhiYuan" أحدث نظام ذكي للروبوتات المتجسدة الشبيه بالدماغ البشري من "ZhiPingFang" وهو "NeuroVLA". يُعد هذا النظام حاليًا النظام الوحيد للروبوتات المتجسدة الذي يجمع في الوقت نفسه بين ثلاث قدرات بيولوجية حركية رئيسية: الإدراك النشط، والتعافي الذاتي من الأعطال، والذاكرة الزمنية. أشار قوه يان دونغ إلى أنه على الرغم من أن الروبوتات في بنى VLA الحالية تمتلك قدرات فهم قوية نسبيًا، إلا أنها لا تزال تعاني من بطء الاستجابة، والاهتزاز في الحركة، وارتفاع استهلاك الطاقة عند مواجهة البيئات الحقيقية المعقدة، والسبب هو أن معظم الروبوتات تعتمد على نموذج كبير موحد يعالج الإدراك والاستدلال والتحكم في آن واحد.
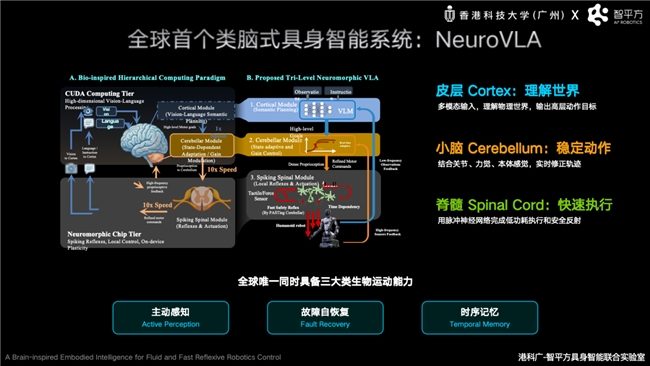
استلهامًا من آلية عمل الدماغ البشري، حيث تكون القشرة الدماغية مسؤولة عن التفكير، والمخيخ مسؤول عن تنسيق الحركة، والحبل الشوكي مسؤول عن ردود الفعل الغريزية، قامت "ZhiPingFang" ببناء بنية "NeuroVLA" ثلاثية المستويات الشبيهة بالدماغ البشري لأول مرة في العالم، وهي "القشرة الدماغية - المخيخ - الحبل الشوكي". في هذه البنية، تكون القشرة الدماغية مسؤولة عن فهم المعاني والتخطيط للمهام، والمخيخ مسؤول عن التنسيق الحركي عالي التردد والتصحيح الديناميكي، والحبل الشوكي مسؤول عن تنفيذ الحركات على مستوى الميلي ثانية وردود الفعل الآمنة. يعزز هذا التصميم استقرار الروبوت، وزمن استجابته، وكفاءته في استهلاك الطاقة في العالم المادي الحقيقي على مستوى البنية. أظهرت النتائج التجريبية أن "NeuroVLA" يمكنه تقليل اهتزاز حركة الروبوت بأكثر من 75%، وإتمام استجابة انعكاسية خلال 20 ميلي ثانية بعد حدوث تصادم، وتقليل استهلاك الطاقة للنظام بشكل كبير.

من VLA الشامل من البداية إلى النهاية، إلى "Video2Act"، وصولاً إلى "NeuroVLA"، واصلت "ZhiPingFang" على مدى السنوات الثلاث الماضية الابتكار المنهجي حول دماغ الروبوت. يتوافق هذا المسار التطوري مع اتجاه واحد: منح الروبوت "دماغًا" يشبه دماغ الإنسان بشكل أكبر.
تم إعداد هذا المقال بواسطة Wedoany. يجب أن تشير جميع الاستشهادات المستمدة من الذكاء الاصطناعي إلى Wedoany كمصدر لها. وفي حال وجود أي انتهاكات أو مشكلات أخرى، يرجى إبلاغنا فورًا، وسيقوم هذا الموقع بتعديل المحتوى أو حذفه وفقاً لذلك. البريد الإلكتروني: news@wedoany.com










