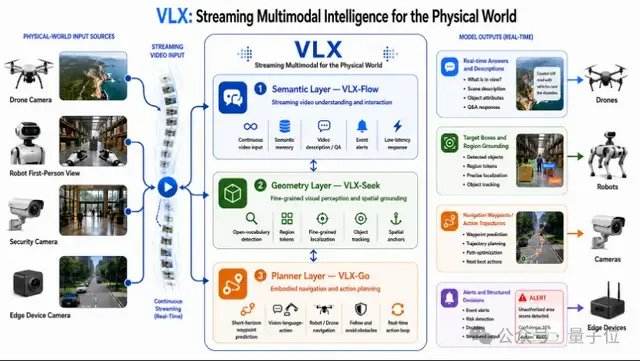
أخبار ar.wedoany.com، أطلقت شركة الذكاء الاصطناعي Om AI، ومقرها مدينة هانغتشو، أول سلسلة نماذج متعددة الوسائط متدفقة على الأجهزة الطرفية في العالم، موجهة نحو العالم المادي، تحت اسم VLX. تتضمن السلسلة ثلاثة نماذج سيتم إطلاقها تباعاً خلال ثلاثة أيام: نموذج VLX-Flow المسؤول عن الإدراك المتدفق في الوقت الفعلي، مما يجعل الفيديو يتدفق باستمرار مثل تيار الماء، حيث يراقب النموذج ويفكر ويحدث حالة العالم في الوقت الفعلي؛ ونموذج VLX-Seek المسؤول عن التحديد الدقيق، للانتقال من مجرد الرؤية إلى الرؤية الواضحة، وسرعة تثبيت الهدف؛ ونموذج VLX-Go المسؤول عن اتخاذ القرارات الحركية، لتحويل نتائج الإدراك والتحديد إلى إجراءات فعلية، وتحديد اتجاه الحركة وخطوات التشغيل بوضوح.
تشكل هذه النماذج الثلاثة معاً حلقة قدرات متكاملة للنموذج متعدد الوسائط، بدءاً من الإدراك المستمر، مروراً بالتحديد الدقيق، وصولاً إلى اتخاذ القرارات الحركية. يتيح التصميم الأصلي للأجهزة الطرفية تشغيل النموذج فعلياً على أجهزة مثل الهواتف المحمولة والطائرات بدون طيار والروبوتات.
لم تكن هذه هي المرة الأولى التي تدخل فيها Om AI مجال اللغة البصرية. ففي العام الماضي، أطلقت الشركة نموذج VLM-R1، وهو أول مشروع مفتوح المصدر في العالم يطبق نموذج التعلم المعزز DeepSeek R1 على نماذج اللغة البصرية. وقد حصل المشروع على أكثر من 2000 نجمة على GitHub خلال 12 ساعة من إطلاقه، وتصدر قائمة الاتجاهات العالمية على GitHub خلال 48 ساعة، وحصل حتى الآن على أكثر من 6000 نجمة.
تم تصميم سلسلة VLX حول كلمتين رئيسيتين: الأجهزة الطرفية والتعددية الوسائطية المتدفقة. يشير مفهوم التعددية الوسائطية المتدفقة إلى تمكين الذكاء الاصطناعي من إدراك البيئة بشكل مستمر وفي الوقت الفعلي في العالم المادي، وتشكيل سلسلة قدرات كاملة من الإدراك إلى التحديد الدقيق وصولاً إلى الحركة. يختلف هذا عن التعددية الوسائطية المتدفقة في المساعدات الصوتية، التي تركز على التفاعل الفوري بين الإنسان والذكاء الاصطناعي، بينما تركز VLX على قيام الذكاء الاصطناعي بمراقبة العالم المادي بشكل مستمر، واتخاذ الأحكام، ودفع الإجراءات، لإتمام الانتقال من مجرد رؤية الصور إلى تنفيذ المهام. مع التطور السريع في مجالات مثل الذكاء المجسد والذكاء المكاني وتوليد الفيديو، لم تعد نماذج اللغة البصرية مجرد وحدة قدرات لنماذج اللغة، بل أصبحت تدريجياً بنية تحتية جديدة للفهم المكاني وفهم الفيديو وحتى تخطيط الحركة. تظهر بيانات مؤتمر CVPR لهذا العام أن نسبة الأوراق البحثية المتعلقة بنماذج اللغة البصرية والتعددية الوسائطية قد ارتفعت من 4.9% في العام الماضي إلى 10.6%، مما يجعلها واحدة من أسرع المجالات البحثية نمواً في السنوات الأخيرة، حيث يعتبر الإدراك في الوقت الفعلي والتحديد الدقيق الكلمتين الرئيسيتين الأكثر استحقاقاً للاهتمام.
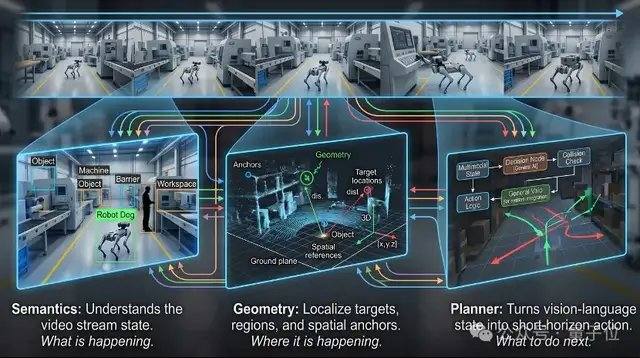
نموذج VLX-Flow مسؤول عن الإدراك المستمر. في العالم الحقيقي، تكون الأشياء في حالة حركة دائمة، وتتغير البيئة باستمرار، وتتبدل زوايا الرؤية بشكل متكرر، مما يجعل الملاحظة لمرة واحدة غير كافية للتعامل مع بيئة ديناميكية ومفتوحة ومتغيرة باستمرار. غالباً ما تقوم نماذج الفيديو التقليدية بتقسيم الفيديو بأكمله إلى إطارات وإرسالها دفعة واحدة إلى النموذج للفهم دون اتصال، مما يؤدي إلى ارتفاع حاد في التكاليف الحسابية مع طول الفيديو، بالإضافة إلى احتمالية فقدان المعلومات السابقة. يعتمد نموذج Flow على المعالجة المتدفقة، حيث تتدفق الصور باستمرار مثل تيار الماء، ويعتمد على الترميز المتزايد وآلية التخزين المؤقت لتحديث الحالة البصرية باستمرار، دون الحاجة إلى إعادة حساب التاريخ بشكل متكرر، ودون فقدان الذاكرة مع زيادة طول الفيديو. من الناحية التقنية، يستخدم Flow آلية الانتباه الخطي (Linear Attention) بدلاً من الانتباه القياسي، بالإضافة إلى آلية ذاكرة مزدوجة الطبقات، مما يسمح لتيار الفيديو بالدخول المستمر إلى النموذج دون أن يؤدي نمو السياق إلى انفجار في الذاكرة.

نموذج VLX-Seek مسؤول عن الإدراك الدقيق. العديد من نماذج اللغة البصرية العامة، على الرغم من براعتها في فهم المعاني عالية المستوى، إلا أن أداءها محدود في مهام مثل التحديد الدقيق، والكشف عن المفردات المفتوحة، والتحديد الدقيق (Grounding). تعتمد الطرق التقليدية على أسلوب الانحدار الذاتي، حيث تتنبأ بموقع الهدف إحداثياً تلو الآخر، مما يؤدي إلى بطء السرعة واحتمالية الانحراف. يغير نموذج Seek هذا النهج، حيث لم يعد يخمن الإحداثيات، بل يقوم أولاً بتوليد مناطق مرشحة، ثم يكمل عملية البحث والمطابقة، محولاً عملية التحديد إلى اختيار منطقة. بشكل أكثر تحديداً، يستخدم Seek رموز المناطق (Region Token) بدلاً من توليد الإحداثيات التقليدية، مما يقلل بشكل كبير من حجم النموذج وتكاليف النشر على الأجهزة الطرفية مع الحفاظ على القدرة على التعرف. هذا الأسلوب يتوافق بشكل أكبر مع طبيعة مهام الإدراك البصري، وبالتالي حتى مع حجم نموذج أصغر، يمكنه الحفاظ على أداء مستقر في مهام مثل الكشف عن المفردات المفتوحة، والتحديد الدقيق، والتتبع في الوقت الفعلي.

نموذج VLX-Go مسؤول عن الحركة. حتى إذا عرفت نماذج اللغة البصرية التقليدية أن الهدف يقع في الجهة اليسرى الأمامية، فإنها في النهاية تقتصر في الغالب على مرحلة الإجابة النصية، ولا يزال هناك حاجة إلى نظام تحكم إضافي للتحرك فعلياً نحو الهدف، وتجنب العوائق، ومتابعة الهدف باستمرار. يقوم نموذج Go بمعالجة الفيديو أحادي العين، والذاكرة البصرية التاريخية، والأوامر باللغة الطبيعية كمدخلات، ويحولها مباشرة إلى نقاط مسار قصيرة المدى قابلة للتنفيذ بواسطة الروبوت، ويتنبأ بكيفية الحركة في فترة زمنية قصيرة قادمة، بدلاً من مجرد إخراج اقتراحات نصية. يجمع Go بين تعلم المسار دون اتصال بالإنترنت والتعلم المعزز عبر الإنترنت، ويصحح استراتيجية الحركة باستمرار في حلقة مغلقة للمحاكاة، مما يمكن الروبوت من تعديل المسار باستمرار بناءً على التغذية الراجعة البصرية في الوقت الفعلي، والحفاظ على أداء مستقر في مهام مثل تتبع الهدف، والملاحة، وتجنب العوائق الديناميكية. لتلبية متطلبات التحكم في الوقت الفعلي على الأجهزة الطرفية، يعتمد Go على خطة تنبؤ خفيفة الوزن لنقاط المسار قصيرة المدى، باستخدام 0.6 مليار معلمة فقط لإكمال تخطيط الحركة في الوقت الفعلي.
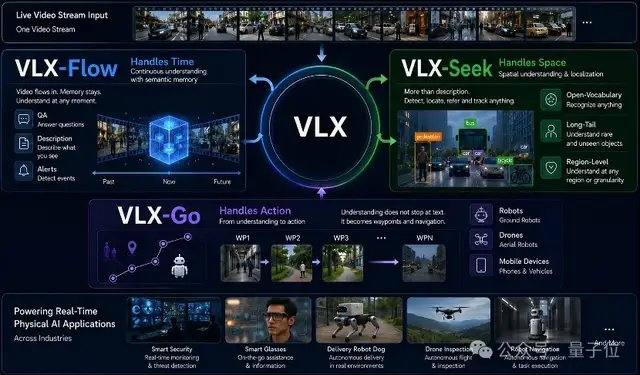
النماذج الثلاثة Flow وSeek وGo ليست مستقلة عن بعضها البعض، بل تشترك في نفس القاعدة الأساسية، وتتعاون بشكل متكامل من البداية إلى النهاية على نفس تيار الفيديو. من الإدراك المستمر إلى التحديد الدقيق وصولاً إلى اتخاذ القرارات الحركية، تشكل هذه النماذج الثلاثة معاً سلسلة قدرات كاملة لـ VLX موجهة نحو العالم المادي.
بالنسبة للأجهزة في العالم المادي مثل الروبوتات والطائرات بدون طيار والكاميرات، فإن النشر على الأجهزة الطرفية هو شرط أساسي للتطبيق الفعلي للنموذج. العديد من نماذج التعددية الوسائطية السحابية، على الرغم من قوتها الكافية، إلا أنها ليست مناسبة بطبيعتها للروبوتات وسيناريوهات الذكاء المجسد، لأن العالم الحقيقي مستمر وديناميكي ومحدود الموارد. النهج الشائع في الصناعة هو تدريب نموذج كبير قدر الإمكان أولاً، ثم ضغطه للتشغيل على الأجهزة الطرفية من خلال التكميم والتقطير وغيرها من الطرق. اختارت VLX مساراً مختلفاً، حيث أعادت تصميم النظام بأكمله منذ البداية وفقاً لقيود القدرة الحاسوبية للأجهزة الطرفية، حيث تم تصميم بنية النموذج وطريقة الاستدلال وسلسلة النشر جميعها حول تيار الفيديو في الوقت الفعلي والأجهزة الطرفية.
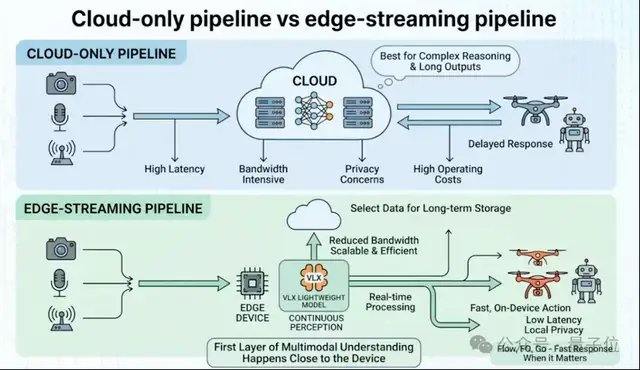
تظهر البيانات أن نموذج VLX-Flow يحتاج فقط إلى 0.06 ثانية لمعالجة تيار فيديو واحد، مع القدرة على معالجة تيارات فيديو متعددة بشكل مستقر؛ ويحقق نموذج VLX-Go أداءً ملاحياً أفضل من النماذج الأكبر حجماً باستخدام حوالي عُشر عدد المعلمات فقط؛ ويحقق نموذج VLX-Seek، بحجم 3 مليارات معلمة، نتائج في مهام مثل الكشف عن الأهداف تعادل أو تتجاوز نتائج النماذج العامة الأكبر حجماً.

Om AI هي شركة ذكاء اصطناعي من مدينة هانغتشو، المؤسس والرئيس التنفيذي تشاو تيان تشنغ حاصل على درجة الدكتوراه في علوم الكمبيوتر من جامعة كارنيجي ميلون، وهو حائز على جائزة وو وينجون للتقدم العلمي والتكنولوجي في الذكاء الاصطناعي. يأتي أعضاء الفريق من مؤسسات مثل جامعة كارنيجي ميلون، وجامعة تسينغهوا، وجامعة تشجيانغ، ومايكروسوفت، وAlibaba Cloud، ولديهم أكثر من 50 ورقة بحثية في المؤتمرات الرائدة وأكثر من 50 براءة اختراع. في عام 2022، حصلت Om AI على أول شهادة نموذج متعدد الوسائط من وزارة الصناعة وتكنولوجيا المعلومات الصينية. إصدار VLX هذا هو أحدث نتائج الشركة حول هدف الإدراك المستمر والتحديد الدقيق والحركة الفعلية.

تم إعداد هذا المقال بواسطة Wedoany. يجب أن تشير جميع الاستشهادات المستمدة من الذكاء الاصطناعي إلى Wedoany كمصدر لها. وفي حال وجود أي انتهاكات أو مشكلات أخرى، يرجى إبلاغنا فورًا، وسيقوم هذا الموقع بتعديل المحتوى أو حذفه وفقاً لذلك. البريد الإلكتروني: news@wedoany.com