
أخبار ar.wedoany.com، أطلقت شركة Artificial Analysis أول معيار مرجعي مستقل للذكاء الاصطناعي الذاتي تحت اسم AgentPerf، مما يوفر للمطورين والشركات ومزودي البنية التحتية طريقة موحدة لمقارنة أنظمة الذكاء الاصطناعي الذاتي. أظهرت نتائج الاختبارات الأولية أن منصة NVIDIA Blackwell Ultra NVL72 قد حققت أداءً رائدًا في أعباء عمل الذكاء الاصطناعي الذاتي، حيث بلغ عدد العوامل الذكية المدعومة لكل ميغاواط 20 ضعفًا مقارنة بنظام NVIDIA Hopper.

تختلف أعباء عمل الذكاء الاصطناعي الذاتي اختلافًا جوهريًا عن الذكاء الاصطناعي القائم على الحوار. فإتمام محادثة واحدة يشبه سباق السرعة، حيث يتطلب استدعاءً واحدًا لنموذج اللغة الكبير (LLM) وردًا واحدًا. أما العامل الذكي، فشبيه بسباق التتابع، حيث يقوم بتقسيم الهدف إلى خطوات متعددة ويستمر في العمل حتى إنجاز المهمة.
يؤدي هذا النمط إلى ربط عشرات أو مئات من استدعاءات LLM في سلسلة متصلة، حيث ينقل كل استدعاء سياقًا متزايدًا إلى الاستدعاء التالي، ويقوم في كل مرة بإجراء استدعاءات للأدوات مثل تجميع وتنفيذ الأكواد البرمجية، والبحث في قواعد البيانات، وتصفح الويب. إن تعقيد هذه العملية ليس جمعيًا، بل مضاعف.
هذا الاختلاف بالغ الأهمية لقياس الأداء. تقيس معايير استدلال الذكاء الاصطناعي الحالية استدعاءً واحدًا لـ LLM، أي سرعة استجابة النموذج لطلب فردي وعدد الطلبات التي يمكن للنظام معالجتها في وقت واحد. وهي ليست مصممة لأعباء العمل الذاتية، لأن استدعاءات LLM المتسلسلة، وتأخير استدعاءات الأدوات، والسياق المتزايد تشكل ضغطًا على أنظمة الحوسبة المتسارعة يختلف تمامًا عن استدعاء LLM الفردي.
بالنسبة للشركات التي تقوم ببناء ونشر العوامل الذكية على نطاق واسع، من الضروري فهم سرعة استجابة العامل الذكي، وعدد العوامل التي يمكن نشرها في وقت واحد، وكمية العمل المفيد الذي يمكن للبنية التحتية للذكاء الاصطناعي إنجازه مقابل كل دولار يُستثمر وكل واط من الطاقة الكهربائية.
في الاختبارات الأولية، استخدم AgentPerf نموذج DeepSeek V4 Pro (وهو نموذج هجين كبير من الخبراء، يمثل الفئة الحالية من النماذج المتطورة التي تقود أقوى العوامل الذكية) لقياس الأداء الذاتي. تحت هذا العبء، حققت منصة NVIDIA GB300 NVL72 أعلى أداء في الاختبارات المرجعية، حيث كان عدد العوامل الذكية المدعومة لكل ميغاواط 20 ضعفًا مقارنة بنظام NVIDIA HGX H200.
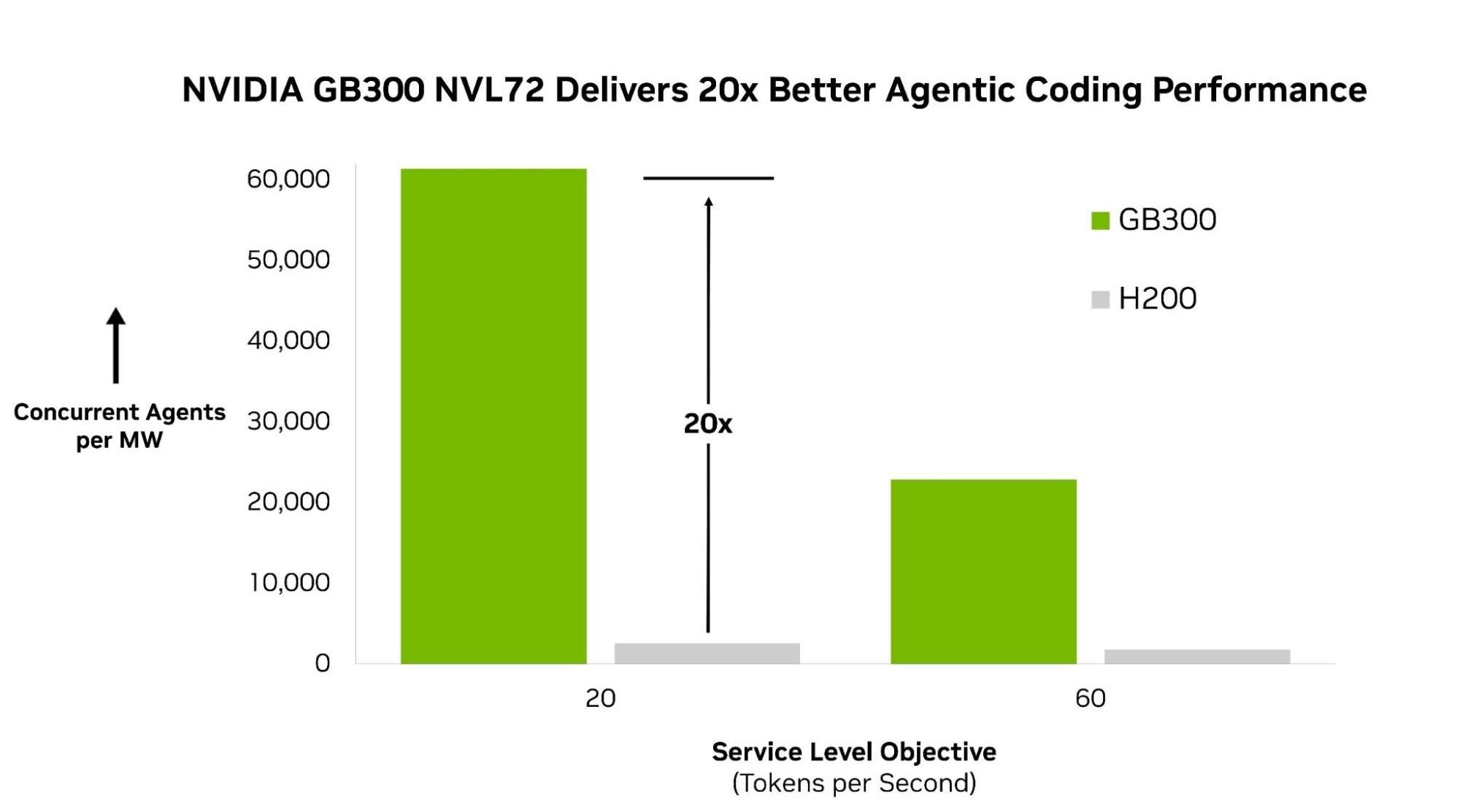
ينبع هذا التفوق في الأداء من التصميم المتكامل فائق التنسيق على مستوى الحزمة الكاملة. يربط نظام GB300 NVL72 بين 72 وحدة معالجة رسومية (GPU) لتشكيل نظام على مستوى الرف، مما يسمح لنماذج MoE الكبيرة مثل DeepSeek V4 Pro بالتوزيع والتنفيذ بكفاءة على نطاق واسع. تعمل نوى CUDA على تسريع الأداء من خلال تداخل الاتصالات مع العمليات الحسابية، وبالتالي يتم استيعاب تكلفة التنسيق عبر الخبراء بدلاً من زيادة زمن الاستجابة. مع توسع نطاق جلسات العوامل الذكية المتزامنة، يحافظ NVIDIA TensorRT LLM على كفاءته من خلال فصل معالجة الإدخال عن توليد المخرجات، مما يتيح تحسين كل مرحلة بشكل مستقل. تستند هذه النتائج إلى منهجية اختبار مرجعية تم بناؤها من الصفر لتعكس الطريقة الفعلية التي يعمل بها الذكاء الاصطناعي الذاتي في بيئات الإنتاج.
تم بناء AgentPerf بناءً على مسارات عمل حقيقية للعوامل الذكية في مجال البرمجة. يتلقى العامل الذكي المهام، ويقرأ الملفات، ويكتب ويحرر الأكواد البرمجية، وينفذ الأوامر، ويكرر العملية بناءً على النتائج. جميع البيانات مستمدة من مستودعات أكواد عامة حقيقية بأكثر من 12 لغة برمجة. تمثل أطوال التسلسل الطويلة، وأنماط استدعاء الأدوات، وزمن الاستجابة سير العمل البرمجي في العالم الحقيقي. يقيس AgentPerf عدد المهام الذاتية التي يمكن للمنصة دعمها في وقت واحد مع الالتزام بعتبات أداء محددة مسبقًا مثل الاستجابة ومعدل إخراج الرموز (tokens). لم يتم تنفيذ استدعاءات الأدوات فعليًا، بل تمت محاكاتها باستخدام أوقات معالجة CPU تمثيلية، وبالتالي فإن الاختلافات في النتائج تعكس فقط تأثير أداء الحوسبة المتسارعة. يمكن تحويل النتائج مباشرة إلى قرارات تتعلق بالبنية التحتية: عدد المهام الذاتية المتزامنة التي يمكن تشغيلها لكل مسرع ولكل ميغاواط من الطاقة.
يقوم مزودو خدمات الاستدلال الرائدون، بما في ذلك Baseten و DeepInfra و Together AI، بالفعل بتقديم خدمات لأعباء العمل الذاتية على النماذج المتطورة (مثل DeepSeek V4 Pro) على منصة NVIDIA Blackwell. توفر Together AI استدلالًا فوريًا على منصة NVIDIA Blackwell لصالح Cursor، وهي منصة برمجة ذاتية مدعومة بالذكاء الاصطناعي. تقوم العوامل الذكية لـ Cursor بتصحيح الأخطاء، وتوليد الوظائف، وإجراء إعادة الهيكلة أثناء استمرار المطورين في العمل. تدعم DeepInfra منصة Pam.ai، وهي منصة قوى عاملة ذكاء اصطناعي موجهة لوكلاء السيارات، حيث تقوم بنشر عوامل ذكية بالكامل على منصة NVIDIA Blackwell لحجز مواعيد الخدمة، ومعالجة المكالمات الهاتفية، وإجراء حملات مبيعات صادرة. مع استمرار NVIDIA والنظام البيئي مفتوح المصدر في تحسين برامج الاستدلال، ستستمر كفاءة وأداء أعباء العمل الذاتية في التحسن. دخلت بنية NVIDIA Vera Rubin الآن مرحلة الإنتاج الكامل، مما سيوفر الجيل التالي من سعة البنية التحتية لتلبية الطلب المتزايد على الذكاء الاصطناعي الذاتي واسع النطاق. لمزيد من التفاصيل حول منهجية AgentPerf والتحسينات على مستوى الحزمة الكاملة، يمكن الرجوع إلى المدونة التقنية ذات الصلة.
تم إعداد هذا المقال بواسطة Wedoany. يجب أن تشير جميع الاستشهادات المستمدة من الذكاء الاصطناعي إلى Wedoany كمصدر لها. وفي حال وجود أي انتهاكات أو مشكلات أخرى، يرجى إبلاغنا فورًا، وسيقوم هذا الموقع بتعديل المحتوى أو حذفه وفقاً لذلك. البريد الإلكتروني: news@wedoany.com










